![]()
4.5
– Caracterização do DVB-T: Codificador de fonte:

O codificador de fonte é provavelmente o grande responsável pelo sucesso
dos sistemas baseados em transmissão digital de sinais. Se só se utilizasse
digitalização do tipo PCM, para transmitir um sinal de vídeo semelhante ao
analógico, seria necessário um ritmo binário de cerca de 166Mbit/s,
significando que a banda a disponibilizar teria de ser maior, do que para um
serviço típico analógico. Este facto corrobora a importância do codificador de
fonte, que vai permitir factores de compressão elevados, só possível utilizando
sinais digitais e permitindo que estes sistemas estejam a substituir todos os
serviços que até aqui eram analógicos.
A norma de compressão de vídeo usada nos vários sistemas de Tv digital,
é a norma MPEG-2 (Moving Pictures Experts Group), uma norma ISO desenvolvida em
parceria com a ITU-T, designada por “Recomendação H.262”. Comum a todas as normas,
o objectivo passa por permitir operacionalidade entre os vários serviços e
sistemas digitais. No seguimento desta ideia, a norma MPEG-2 é pois uma
extensão da norma MPEG-1, de forma a poder transmitir-se sinais digitais de
televisão de média e alta qualidade.
A norma MPEG-2, seria só por si, um motivo para a execução
de um trabalho semelhante a este, devido quer á sua complexidade, quer extensão.
Não sendo possível reunir toda a informação no âmbito deste trabalho, focam-se de
seguida os aspectos que mais influenciam um sistema de difusão de televisão
digital terrestre.
4.5.1
– Codificador de fonte. MPEG-2 Sistema:
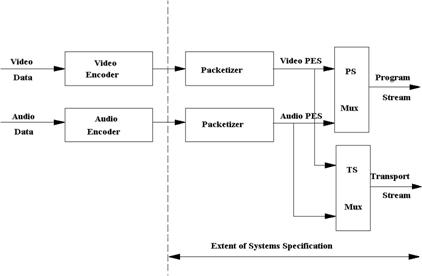 A primeira parte da norma
corresponde ao Sistema, que permite a multiplexagem, sincronização e protecção
dos fluxos elementares codificados, que são o áudio, vídeo e dados. A imagem
seguinte representa um possível esquema básico de um sistema MPEG-2.
A primeira parte da norma
corresponde ao Sistema, que permite a multiplexagem, sincronização e protecção
dos fluxos elementares codificados, que são o áudio, vídeo e dados. A imagem
seguinte representa um possível esquema básico de um sistema MPEG-2.
Fig. 3.5.1: MPEG-2
Sistema.
A codificação de uma stream elementar de áudio ou vídeo
(sinal original), vai permitir formar um pacote de dados com requisitos
temporais semelhantes aos do sinal original. Estes pacotes vão de seguida ser
transformados, por conveniência do tamanho dos blocos de dados, num Packetized
Elementary Stream (PES). Estes PES, para alem dos campos para transporte de
dados possuem informação de controlo em campos criados para o efeito, como se
pode observar na figura 3.5.2.
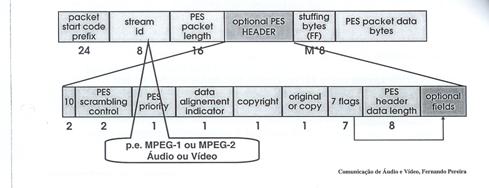
Fig. 3.5.2: Estrutura
do PES.
O MPEG-2 sistema permite, que os vários PES de áudio e
vídeo sejam combinados, formando um “Program Stream” com um fluxo digital
contendo apenas uma base de tempo para todos os fluxos multiplexados. O fluxo
resultante tem um tamanho variável e é usado sobretudo para armazenamento de
informação em canais sem erros, tais como o DVD. O “Program Stream” serve pois
sobretudo para criar compatibilidade entre esta norma e o MPEG-1.
Para a transmissão de Tv digital, é usado o “Transport
Stream” que é originado por vários PES, sendo posteriormente subdivididos em
pacotes menores (figura 3.5.4). Cada programa de Tv vai ser constituído por
vários destes pacotes. Por esta razão, o fluxo de dados vai incluir várias
bases de tempo, possível graças ao facto de o “Transport Stream” ter um
mecanismo que permite a transmissão de múltiplos sinais de relógio PCR (“Program
Clock Reference”). Cada programa é mais tarde regenerado no descodificador
graças ao PCR.
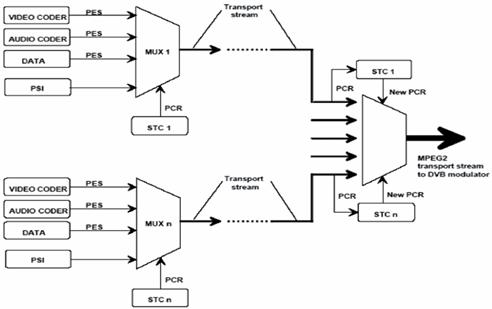
Fig. 3.5.3: MPEG-2
Transport Stream.
Mas um fluxo do tipo “Transport Stream” é mais que uma
simples multiplexagem de áudio e vídeo, uma vez que inclui campos na trama
capazes de descrever o Stream de dados. É o caso do PAT (“Program Association
Table”), que permite listar todos os programas que estão no “Transport Stream”.
Por sua vez cada entrada para o PAT, aponta para o PMT (“Program Map Table”),
que permite listar todas as streams que fazem parte de um determinado programa
de Tv. Alguns programas são abertos e utilizados, mas outros poderão estar
protegidos através de técnicas de encriptação.

O “Transport Stream” consiste portanto, num número fixo de
pacotes, que têm obrigatoriamente de ter 188 Bytes. Cada pacote tem um
identificador designado por PID. Pacotes da mesma PES têm o mesmo ID,
possibilitando ao descodificador que escolha os pacotes que pretende,
rejeitando os que não lhe servem dentro do “Transport Stream”. Para que tudo
corra de forma eficaz, é necessário que haja sincronização, permitindo ao
descodificador identificar o início de cada pacote.
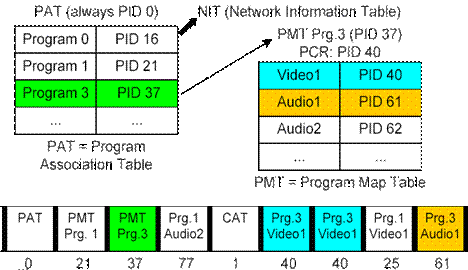
Fig. 3.5.4: Estrutura
do Transport Stream.
Tal como se pode observar pela figura 3.5.4, um sistema de
“Transport Stream”, pode ter ainda o NIT (Network Information Table), cujo ID
se encontra no programa 0 da PAT, que quando utilizado serve para fornecer
informação sobre a rede fixa, tal como a frequência dos vários canais,
fornecedor do serviço, redes alternativas disponíveis, etc. Por fim, podemos
ter ainda o CAT (Conditional Access Table), um campo obrigatório quando temos
um PES protegido num “Transport Stream”. Serve para fornecer ao sistema
informação de protecção e gestão.
4.5.2 – Codificador de fonte: Compressão DCT:
No caso do DVB, e tal como noutros serviços digitais, a compressão dos
sinais multimédia, é sobretudo resultado da aplicação de técnicas que permitem
eliminar a redundância e a irrelevância do sinal original. A redundância
permite relacionar as semelhanças e preditabilidade das amostras correspondentes
á informação, havendo preservação da informação durante a codificação. A
irrelevância permite retirar informação que não é perceptível para o sistema
auditivo ou visual humano, é pois um processo que introduz perdas e é
irreversível do ponto de vista matemático. No entanto, na maioria dos casos, a
qualidade subjectiva permanece inalterada. (Qualidade Transparente).
No caso do MPEG, os grandes factores de compressão
devem-se sobretudo á exploração da redundância espacial entre imagens
consecutivas. No entanto os conteúdos MPEG são formados por imagens. A técnica
mais utilizada para a compressão das imagens é a DCT (Discrete Fourier
Transform), que consiste numa transformada de Fourier para Amostras discretas.
Esta técnica, muito robusta, permite decompor um sinal que é contínuo no tempo,
numa série de sinais harmónicos do tipo coseno e seno.
No caso de uma imagem, o sinal que a representa é
bidimensional, o que também vai originar uma DCT com duas dimensões (matriz
2*2). De forma a reduzir a complexidade e o tempo de processamento a imagem é
dividida, geralmente em blocos de 8 por 8 pixels, conduzindo a uma transformada
DCT também de 8 por 8 pixels. (Observe-se a figura 3.5.6).
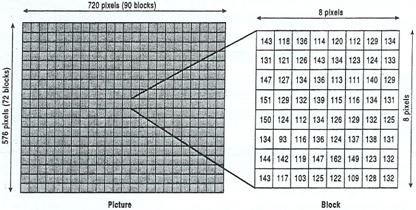
Fig. 3.5.6: Divisão
da imagem em blocos de 8*8 pixel.
Observando a imagem anterior, podemos ver que cada bloco
contém uma informação numérica, que corresponde ao valor da luminância de cada
pixel.
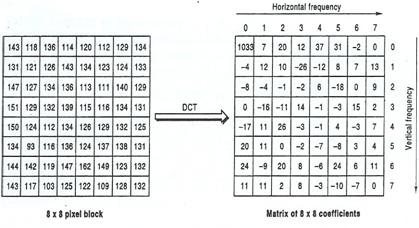
Fig. 3.5.6:
Transformação do bloco da imagem
Podemos observar que os 64 pixéis são transformados em 64
coeficientes DCT. O primeiro coeficiente, posição (0,0) na matriz, corresponde
á componente DC do sinal. Isto significa que se o bloco fosse constituído por
apenas um padrão, então ele seria representado apenas pelo primeiro coeficiente
DCT da matriz. Da mesma forma, os padrões com menos detalhe no bloco a
codificar, são representados pelos coeficientes que estão na parte superior
esquerda da matriz, (coeficientes de baixa frequência), enquanto que os blocos
que apresentam padrões com mais detalhe, são representados pelos coeficientes
que se encontram na parte inferior direita da matriz (coeficientes de alta
frequência).
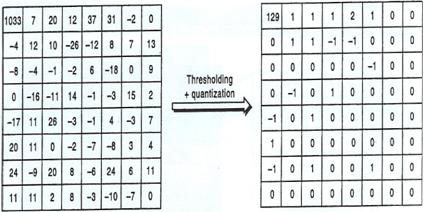
Fig. 3.5.6:Contribuição
de cada Coeficiente da DCT para o padrão do bloco.
A DCT é pois uma técnica, que tem a capacidade de concentrar
a energia do bloco, num pequeno número de coeficientes. Para além disso, os
coeficientes não estão correlacionados entre si, ou seja a informação da imagem
é expressada de forma independente por cada coeficiente.
Até aqui não há nenhuma informação perdida, sendo que o
processo inverso poderia ser executado. No entanto quando se pretende alcançar
factores de compressão mais elevados, a DCT “arruma” a informação de forma
muito eficiente. Este facto possibilita que se eliminem coeficientes, tendo em
conta quer os seus valores quer a sua frequência, sem que ocorra uma degradação
perceptível da qualidade da imagem.
No entanto, como há perda de informação, cria-se um
processo matematicamente irreversível, isto é, deixa de ser possível
reconstruir a imagem original, tal como ela era no início.
A compressão do sinal assenta prioritariamente em dois
processos:
![]() Primeiro
eliminam-se os coeficientes irrelevantes da DCT, substituindo-os por zero (Thresholding).
No processo de eliminação, para que a imagem não perca qualidade subjectiva,
devem-se eliminar os coeficientes com menor valor em módulo e devem-se eliminar
os de maior frequência. Tal como foi referido, os coeficientes de maior
frequência, traduzem padrões mais complexos, que á escala do bloco são
imperceptíveis para olho humano.
Primeiro
eliminam-se os coeficientes irrelevantes da DCT, substituindo-os por zero (Thresholding).
No processo de eliminação, para que a imagem não perca qualidade subjectiva,
devem-se eliminar os coeficientes com menor valor em módulo e devem-se eliminar
os de maior frequência. Tal como foi referido, os coeficientes de maior
frequência, traduzem padrões mais complexos, que á escala do bloco são
imperceptíveis para olho humano.
![]() Os
coeficientes que sobram, são de seguida quantificados, permitindo uma vez mais
diminuir a quantidade de informação a ser codificada. Uma boa estratégia é
utilizar passos de quantificação mais pequenos nas baixas frequências, enquanto
que nas altas devem ser utilizados passos de quantificação maiores, pelas
mesmas razões do ponto anterior.
Os
coeficientes que sobram, são de seguida quantificados, permitindo uma vez mais
diminuir a quantidade de informação a ser codificada. Uma boa estratégia é
utilizar passos de quantificação mais pequenos nas baixas frequências, enquanto
que nas altas devem ser utilizados passos de quantificação maiores, pelas
mesmas razões do ponto anterior.
A quantificação e o thresholding devem ser dinamicamente
regulados, tendo em conta o ritmo binário pretendido após a codificação.
4.5.4
– Codificador de fonte. MPEG-2 Video: Compressão
Tal como foi referido, a principal forma de obter elevados
factores de compressão, é usar a forte correlação que existe entre imagens
sucessivas. Estas técnicas de predição e compensação de movimento, permitem
representar imagens contíguas através das diferenças que existem entre si,
permitindo ao mesmo tempo diminuir a quantidade de informação necessária para
as poder guardar ou transmitir. As imagens usadas na codificação MPEG podem ser
de três tipos.
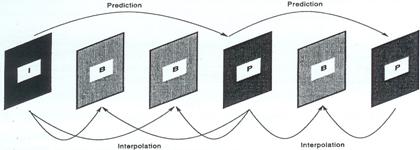
Fig. 3.5.8:
Concatenação possível dos vários tipos de imagem.
![]() Imagens do Tipo I (intra): Estas imagens não referenciam
outras imagens. Por esta razão, têm toda a informação que necessitam para ser
descodificadas de forma independente. São a base de toda a codificação, embora
tenham factores de compressão baixos. Permitem ainda a entrada aleatória por
parte do utilizador, numa secção do vídeo MPEG.
Imagens do Tipo I (intra): Estas imagens não referenciam
outras imagens. Por esta razão, têm toda a informação que necessitam para ser
descodificadas de forma independente. São a base de toda a codificação, embora
tenham factores de compressão baixos. Permitem ainda a entrada aleatória por
parte do utilizador, numa secção do vídeo MPEG.
![]() Imagens do Tipo P (Predição): São codificadas a partir das
imagens I ou P que precedem esta imagem. Usam técnicas de compensação de
movimento, garantindo factores de compressão mais elevados. Porque a
compensação de movimento não é perfeita, não podem haver muitas imagens P entre
duas I.
Imagens do Tipo P (Predição): São codificadas a partir das
imagens I ou P que precedem esta imagem. Usam técnicas de compensação de
movimento, garantindo factores de compressão mais elevados. Porque a
compensação de movimento não é perfeita, não podem haver muitas imagens P entre
duas I.
![]() Imagens do Tipo B
(Bidireccionais): Estas
imagens são codificadas a partir da interpolação entre imagens I e P, que estão
adjacentes a si (Quer na sua traseira, que à sua frente). Como estas imagens
não são utilizadas na interpolação de outro tipo de imagens, elas não propagam
erros e ao mesmo tempo, são as que apresentam um maior ganho de compressão.
Imagens do Tipo B
(Bidireccionais): Estas
imagens são codificadas a partir da interpolação entre imagens I e P, que estão
adjacentes a si (Quer na sua traseira, que à sua frente). Como estas imagens
não são utilizadas na interpolação de outro tipo de imagens, elas não propagam
erros e ao mesmo tempo, são as que apresentam um maior ganho de compressão.
O número de imagens entre duas imagens sucessivas do tipo
I representam um GOB (Group of Pictures), cuja relação com a sequência de
imagens esta representada na figura seguinte.
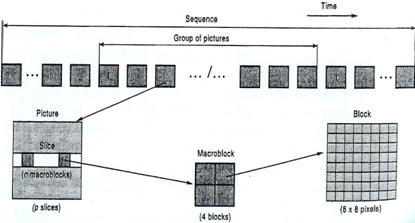
Fig. 3.5.9: Sequência
MPEG
Tal como foi observado ao longo deste ponto, o aspecto
mais importante de um codificador MPEG, reside no seu bloco de compensação de
movimento. Sendo a parte mais complexa do codificador, é ele que vai determinar
a performance particular de cada codificador MPEG. Este facto reside sobretudo
na flexibilidade imposta pela norma, permitindo que diferentes parâmetros sejam
escolhidos tendo em conta o compromisso que existe entre complexidade,
compressão e qualidade.
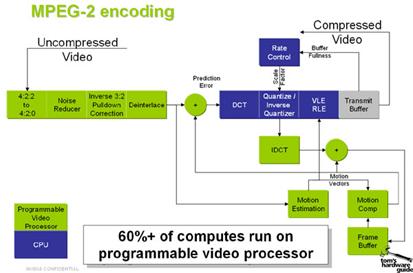
Fig. 3.5.9:
Codificador MPEG-2
Basicamente a compensação de movimento, consiste em
encontrar uma correlação óbvia entre duas zonas distintas, de uma imagem que já
ocorreu e a seguinte. Quando esta correlação é encontrada, origina-se a um
vector de movimento para ser usado no descodificador.
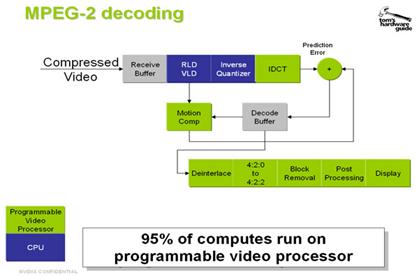
Fig. 3.5.9:
Descodificador MPEG-2
Tal como seria de esperar, a maior parte do processamento,
está toda na parte da descodificação. Este facto é positivo, sobretudo para
evitar elevados custos no equipamento do cliente final.
4.5.5
– Codificador de fonte. MPEG-2 Video: Diferenças.
Num serviço digital terrestre de Tv, as aplicações são
assimétricas sendo possível a construção de codificadores de boa qualidade.
Deste modo os principais requisitos que deve ter o MPEG-2, são os seguintes:
![]() O
sistema deve suportar uma vasta gama de resoluções espaciais e temporais, em
formato entrelaçado e progressivo.
O
sistema deve suportar uma vasta gama de resoluções espaciais e temporais, em
formato entrelaçado e progressivo.
![]() Deve
também ter a capacidade de conter vários formatos de sub amostragem da
crominância (4:4:4, 4:2:2, 4:2:0).
Deve
também ter a capacidade de conter vários formatos de sub amostragem da
crominância (4:4:4, 4:2:2, 4:2:0).
![]() Deve
ter flexibilidade em termos de débito binário.
Deve
ter flexibilidade em termos de débito binário.
![]() Tal
como para outros sistemas do género deve ter diversas facilidades, tais como,
acesso condicionado, leituras rápidas, acesso aleatório, fácil transcodificação
para outras normas, assim como quer compatibilidade directa quer
compatibilidade inversa entre normas. (MPEG-1,H.261).
Tal
como para outros sistemas do género deve ter diversas facilidades, tais como,
acesso condicionado, leituras rápidas, acesso aleatório, fácil transcodificação
para outras normas, assim como quer compatibilidade directa quer
compatibilidade inversa entre normas. (MPEG-1,H.261).
![]() Por
fim, um aspecto muito relevante para o DVB-T, é o facto de a norma dever ter
requisitos que permitam adaptação a vários meios de transmissão, em termos de
sincronização, resistência a erros, entre outros.
Por
fim, um aspecto muito relevante para o DVB-T, é o facto de a norma dever ter
requisitos que permitam adaptação a vários meios de transmissão, em termos de
sincronização, resistência a erros, entre outros.
As grandes diferenças entre as normas MPEG-1 e Mpeg-2 na
área do vídeo, têm a ver sobretudo como entrelaçamento e a escalabilidade.
A escalabilidade tem a ver sobretudo, com a possibilidade
de se obter uma recuperação útil do sinal de vídeo, descodificando apenas algumas
partes da informação comprimindo. É uma característica útil, sobretudo quando
não se consegue garantir os requisitos de débito por parte do descodificador.
O entrelaçamento, permite por sua vez, codificar de forma
mais eficiente o material entrelaçado. Para o efeito, a norma MPEG-2,
classifica as imagens como:
![]() Imagem Trama: Os macroblocos (conjuntos de 4
blocos), a codificar são definidos na trama, pela combinação de dois campos, um
par e outro impar.
Imagem Trama: Os macroblocos (conjuntos de 4
blocos), a codificar são definidos na trama, pela combinação de dois campos, um
par e outro impar.
![]() Imagem Campo: Os macroblocos (conjuntos de 4
blocos), a codificar são definidos em cada um dos campos, par e ímpar. (ver
figura 3.5.10)
Imagem Campo: Os macroblocos (conjuntos de 4
blocos), a codificar são definidos em cada um dos campos, par e ímpar. (ver
figura 3.5.10)
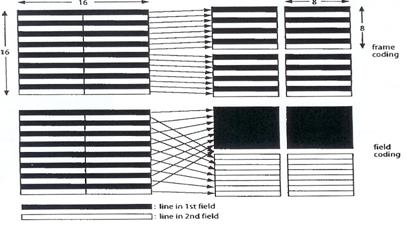
Fig. 3.5.10: A) Modo
de Trama B) Modo de Campo
A
codificação usando conteúdos entrelaçados, vai usar diferentes modos de
predição, consoante a aplicação que se pretende usar:
![]() Modo Trama para Imagens Trama: Corresponde basicamente ás técnicas anteriormente
estudadas, usando para a codificação tramas I, P e B. Temos bons resultados
para conteúdos com movimento moderado.
Modo Trama para Imagens Trama: Corresponde basicamente ás técnicas anteriormente
estudadas, usando para a codificação tramas I, P e B. Temos bons resultados
para conteúdos com movimento moderado.
![]() Modo Campo para Imagens Campo: É semelhante ao modo anterior, mas os vários
macroblocos e predições, são definidas em cada campo separadamente.
Modo Campo para Imagens Campo: É semelhante ao modo anterior, mas os vários
macroblocos e predições, são definidas em cada campo separadamente.
![]() Modo Campo para Imagens Trama: Cada macrobloco na imagem trama é dividido nos pixels
correspondentes ao campo par e campo impar, fazendo-se a predição de matrizes
16×8 tendo como base um dos campos par ou impar.
Modo Campo para Imagens Trama: Cada macrobloco na imagem trama é dividido nos pixels
correspondentes ao campo par e campo impar, fazendo-se a predição de matrizes
16×8 tendo como base um dos campos par ou impar.
![]() Blocos 16×8 para Imagens Campo: Este modo de predição, permite atribuir um vector de
movimento a cada uma das metades de cada macrobloco num dado campo.
Blocos 16×8 para Imagens Campo: Este modo de predição, permite atribuir um vector de
movimento a cada uma das metades de cada macrobloco num dado campo.
4.5.6–
Codificador de fonte. MPEG-2 Áudio: Compressão.
Por fim temos a parte de Áudio. A compressão desta
componente do sinal deve-se sobretudo, á aplicação de métodos capazes de
explorar particularidades da percepção auditiva humana, eliminando informação
que não é audível para a maioria das pessoas.
Existem duas normas MPEG-2 áudio:
![]() Áudio
(Parte 2) – Esta norma permite codificar até 5 canais, mais um de baixa
frequência. A todos os canais oferece alta qualidade, a um débito de 384
kbits/s. Um dado muito importante, reside no facto de a norma oferecer
compatibilidade do tipo “backward” e “forward” com a norma MPEG-1 áudio. Por
esta razão, esta norma é frequentemente designada por MPEG-2 BC (Backward e Forward).
Áudio
(Parte 2) – Esta norma permite codificar até 5 canais, mais um de baixa
frequência. A todos os canais oferece alta qualidade, a um débito de 384
kbits/s. Um dado muito importante, reside no facto de a norma oferecer
compatibilidade do tipo “backward” e “forward” com a norma MPEG-1 áudio. Por
esta razão, esta norma é frequentemente designada por MPEG-2 BC (Backward e Forward).
![]() Codificação
de Áudio Avançado (Parte 7) – Esta norma prescinde de qualquer compatibilidade
com a norma MPEG-1 Áudio, obtendo maior qualidade para o mesmo débito que a
norma anterior. Por esta razão, esta norma também é frequentemente designada
por MPEG-2 NBC (Non Backward Compatible).
Codificação
de Áudio Avançado (Parte 7) – Esta norma prescinde de qualquer compatibilidade
com a norma MPEG-1 Áudio, obtendo maior qualidade para o mesmo débito que a
norma anterior. Por esta razão, esta norma também é frequentemente designada
por MPEG-2 NBC (Non Backward Compatible).
4.6–
Considerações Finais.
Recentemente tem-se proposto a utilização de uma outra
norma de codificação de sinal para transmissão digital terrestre. A norma
MPEG-4 AVC (também conhecida por H.264) recentemente desenvolvida, permite um
ganho de compressão de aproximadamente 50% em termos de eficiência ou qualidade
em relação às norma MPEG-2. Este aumento da eficiência da codificação é devido
à maior complexidade da codificação, designadamente em termos de estimação de
movimento e escolha do modo de codificação com predição multi-trama. A ser
implementada, esta norma permitiria diminuir a banda necessária para transmitir
um canal, aumentando a capacidade do sistema, sem grandes alterações da rede,
uma vez que a codificação só se dá na fonte.