AUDIÇÃO HUMANA
Sabe-se que a audição humana não é perfeita. Existem limitações fisicas no aparelho auditivo mas tambem o som tem que percorrer o trajecto através dos nervos até ao cérebro, nomeadamente o cortéx auditivo, onde se efectua o seu processamento. Limitações como estas possibilitam que que alguma informação de audio seja ignorada sem que o que ouvimos seja afectado. O formato MP3 explora actualmente as imperfeições de limiares da audição, redundância estereofónica e mascaramento, que se descreve de seguida.
LIMIARES DA AUDIÇÃO
Se dois sons tiverem a mesma amplitude, dependendo das suas frequências, podem ser perceptíveis com intensidade distinta. Á minima intensidade que um determinado som tem de ter para que seja ouvido, chama-se limiar de sensibilidade. Ao se observar a Fig.1, constata-se que na zona dos 1kHz-5kHz o ouvido humano tem mais sensibilidade ao som. Praticamente todos os pontos da curva de audibilidade mí nima são perceptíveis com igual intensidade. O ouvido humano tem sensibilidade a sons para as frequências na banda de 20Hz-20kHz, diminuindo esta sensibilidade ao envelhecer.
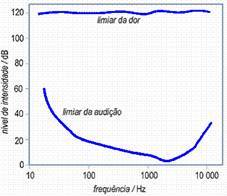
Fig.1 limiares da audição do aparelho auditivo humano
Temos ainda o limiar da dor, que é dado pela intensidade de som a partir da qual os sons causam dor e eventualmente danos no aparelho auditivo.
REDUNDÂNCIA ESTEREOFONICA
Consiste na direcção do som de baixas frequências não ser detectada pelo ouvido humano.
MASCARAMENTO
Mascaramento auditivo consiste na audibilidade mínima que um determinado som pode ter devido á presença de outro. É dividido em mascaramento temporal e na frequência.
MASCARAMENTO TEMPORAL
Dá-se antes e depois de um som de nível forte. Pré-mascaramento é quando um som é mascarado antes de um som mais forte, se for depois é pós-mascaramento. O pré-mascaramento ocorre durante um periodo de tempo curto, 20ms, o pós-mascaramento tem efeito até 200ms após o som que lhe deu origem.
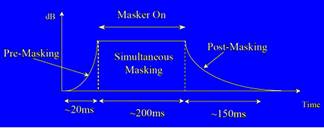
Fig2: Mascaramento temporal
MASCARAMENTO NA FREQUÊNCIA
Para ilustração recorre-se ao seguinte exemplo: se num determinado instante chega ao sistema auditivo humano um som com frequência de 1kHz, forte, e simultaneamente um som com frequência 1.1kHz, estando 18db abaixo do som anterior. O som de 1kHz, mais forte, mascara o som de 1.1kHz, sendo que o som de 1.1kHz não é ouvido. Esta situação ocorre porque o som de 1kHz está perto em frequência sendo forte. Quanto mais perto em frequência estão os sons, mais fortes serão os sons que poderão ser mascarados pelo som que é mais forte.
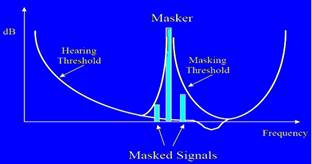
Fig 3: Mascaramento na frequência
Ao se explorar os dois mascaramentos, no tempo e na frequência, é possível uma redução substancial na informação de áudio sem que ocorra uma mudança audível.
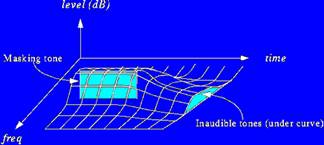
Fig 4: Mascaramento temporal e na frequência
CODIFICAÇÃO
CODIFICAÇÃO AUDIO
São conhecidos dois tipos de codificadores de audio. Os codificadores sem perdas, que tentam reconstruir o sinal exactamente igual ao original tanto quanto seja possível após codificação e descodificação.
Os codificadores perceptivos, não tentam que o sinal seja mantido tal e qual como era antes da codificação e descodificação. Ao aproveitar os conhecimentos do ouvido humano, o codificador perceptivo vai eliminar uma parte do sinal que o ser humano não tem capacidade de ouvir.
A maioria dos codificadores perceptivos fazem a transformação do som no dominio do tempo para o dominio da frequência e separam as várias frequências em sub-bandas. Seguidamente, exploram efeitos de mascaramento, para que seja possível inserir erro no sínal, de modo a que não seja perceptível pelo ouvido humano a seguir á descodificação.
Exemplos de codificadores perceptivos: codificadores de MPEG audio e o codificador que é utilizado no MiniDisc, o ATRAC da Sony.
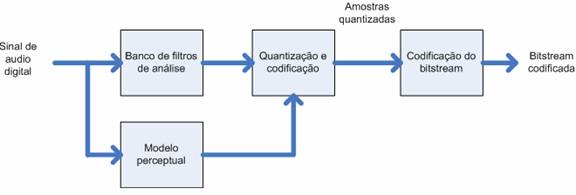
Fig. 5: Diagrama da codificação preceptiva

Fig.6: Diagrama da descodificação preceptiva
CODIFICAÇÃO MP3 (MPEG-1 LAYER 3)
A propriedade mais importante do padrão MPEG consiste no príncipio da minimização nele da quantidade de elementos normativos. Em MPEG1 Audio, tambem no Video, são normativos apenas o descodificador e a representação dos dados no formato do audio comprimido. Na norma o codificador não é especificado, possibilitando que a qualidade dos codificadores evolua no tempo e que sempre se mantenha a compatibilidade com descodificadores menos recentes.
CARACTERISTICAS PRINCIPAIS
O modo de operação pode ser Mono, Stereo, Dual-Stereo, Mono/Stereo (MS) ou Joint-Stereo. Em Stereo a codificação é independente mas existe partilha de campos comuns na trama codificada. Em Dual-Stereo os canais são codificados de uma forma independente, por exemplo, 2 linguas.
No Mono/Stereo (MS) os dois canais são codificados da forma L-R(side) e L+R(middle), permitindo melhorar o controlo da localização espacial do ruído de quantificação. Quando os canais direito e esquerdo têm pouca separação estéreo, ou seja quando são muito parecidos, o canal side contem pouquíssima informação. Em Joint-Stereo acima de 2 kHz, é enviado o sinal L+R e tambem factores de escala para os dois canais L e R, poi o ouvido humano tem pouca sensibilidade. Neste modo são permitidos menores débitos mas existe o perigo de sofrer alterações.
Quanto ás frequências de amostragem na norma MPEG1 Layer 3 constam apenas o uso de 32 kHz, 44.1 kHz (qualidade CD) e 48 kHz.
Em relação ao débito binário o MPEG audio não trabalha apenas a um débito, a selecção do débito (8-320 kbit/s) é segundo o criério do codificador, sendo a mudança de débito efectuada de trama a trama, permitindo codificação com débito fixo ou variável.
ALGORITMO
Na figura seguinte temos o diagrama de blocos do algoritmo de codificação de MP3 (MPEG-1 Layer 3):
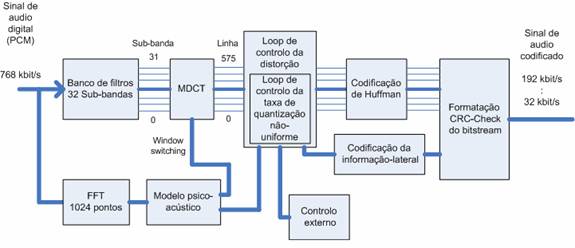
Fig. 7: Diagrama de blocos do codificador MPEG-1 Layer 3
Na entrada temos os dados de audio, estes passam através do banco de filtros que os vai dividir em sub-bandas múltiplas. A filtragem é efectuada em paralelo com aa análise psico-acústica que vai determinar a SMR (relação sinal-máscara) de cada uma das sub-bandas. O bloco de controlo de distorção vai utilizar as SMR para a decisão de como irá dividir o número total de bits de codificação que estão disponiveis. Por fim, são formatadas num bitstream as amostras quantificadas e codificadas, segundo a norma.
Bancos de filtros: Nos bancos de filtros chegam blocos de dados com 1152 amostras, ou seja dois grupos de 576 amostras. Passando pelo banco de filtros, as amostras vão ser divididas em 32 sub-bandas que estão separadas na frequência igualmente. Em cada uma das sub-bandas é aplicada a MDCT (transformada discreta coseno modificada) com o objectivo de compensação da precisão baixa do banco de filtros, através do aumento da sua granulidade. Aplica-se MDCT a cada sub-camada cuja sobreposição nas sub-bandas adjecentes é de 50% para que o efeito de bloco diminua. Pode-se tambem utilizar comutação dinâmica de janela para diminuir o pré-eco (tipo de efeito indesejável que a MDCT introduz).
Modelo-Psicoacustico: É um modelo matemático que representa, simplificadamente, tolerâncias e as propriedades principais do ouvido humano, tais como particularmente o efeito do mascaramento, a percepção da intensidade sonora e a selectividade espectral. É utilizada para a estimação, adapativa do perfil e quantidade do ruído que é possivel injectar no sinal audio sem que se torne perceptível, permitindo a redução do débito associado á representação que foi codificada. Este modelo é o principal factor determinante para que o codificador tenha qualidade.
As suas tarefas são, a decisão do tipo de bloco que vai ser utilizado e o calculo da SMR (relação sinal/máscara), ou seja o valor do sinal na banda a dividir pelo limiar de mascaramento.
Inicialmente converte-se o audio para o dominio da frequência através da utilização da FFT (transformada rápida de fourier) com o intuito de obter-se uma resolução de frequência boa que permita que o cálculo dos limiares de mascaramento seja o correcto. A saida da FFT é utilizada primeiro para a análise do tipo de sinal que está a ser processado. Um sinal mais transitório vai resultar em um bloco curto enquanto que um sinal estacionário faz o modelo escolher um bloco longo. Este tipo de bloco é utilizado posteriormente para calcular a MDCT.
O modelo psico-acústico vai calcular o limiar de mascaramento para cada sub-banda mínimo, utilizando estes mesmos valores para o calculo da SMR. O modelo vai passar da SMR para a secção de controlo de distorção, quantificação e codificação para ser utilizada posteriormente. Na saida do modelo psicoacústico encontram-se os valores para os limiares de mascaramento ou ruído que cada sub-banda permite, sendo equivalente de uma forma aproximada ás bandas criticas da audição do aparelho auditivo humano. Num sinal digital existe ruido de quantificação, porque existe um limitado numero de valores discretos para a representação do sinal original. O resultado da compressão não deverá ser distinguido do sinal se o ruido de quantificação for mantido abaixo do limiar de mascaramento para cada uma das sub-bandas.
Quantificação e Codificação: Mesmo não fazendo parte da norma , utiliza-se normalmente um sistema com dois ciclos iterativos aninhados, ciclo de distorção e débito, na quantificação e codificação dos coeficientes de MDCT. A quantificação faz-se para que os valores maiores sejam codificados de um modo automático com menos exactidão.
Os valores que foram quantificados são codificados através de codificação entrópica de Huffman. Para se obter uma adaptação do processo de codificação a tipo de sinais musicais diferentes, é selecionada uma tabela de Huffman óptima de entre um determinado numero possível de escolhas. Para se obter uma adaptação melhor ás estatisticas dos sinais, pode-se, para diferentes partes do espectro de frequências seleccionar diferentes tabelas de Huffman.
Como a codificação de Huffman é basicamente um método com comprimento de código que é variável e o ruido resultante de quantificação deve ser mantido sob o limiar de mascaramento, um valor de ganho global e factores de escala são aplicado antes da quantificação real. O valor de ganho global determina o tamanho do passo de quantificação e os factores de escala determinam factores da forma do ruido para cada uma das bandas.
O processo para determinar o ganho, os factores de escala de cada banda óptimos para um determinado bloco, o débito e saída a partir do modelo psicoacustico é efectuado pelos laços de iteração exterior relativos á distorção e interior relacionados com o débito.
Ciclo de débito: O código de Huffman designa palavras de código mais curtas ou mais frequentes a valores quantificados menores. Se o número de bits que resulta da codificação exceder o numero de bits que está disponivel para a codificação de um bloco de dados, este pode ser corrigido com o ajuste do ganho global, resultando num passo de quantificação maior, o que conduz a menores valores quantificados.
Esta operação é repetida até que o número de bits para a codificação de Huffman seja suficientemente pequeno. O ajuste do ganho global é efectuado através de factores de escala.
Ciclo de distorção: Aplicam-se factores de escala a cada sub-banda para adaptação do ruído de quantificação ao limiar de mascaramento. O sistema inicia com um factor de escala um. Se o ruido de quantificação numa determinada sub-banda for maior que o ruído permitido(limiar de mascaramento) de acordo com o modelo psicoacustico, o factor de escala para esta banda é ajustado para que o ruido de quantificação seja reduzido.
Para conseguir obter um ruido de quantificação menor requer-se mais passos de quantificação, que origina um debito maior, o ciclo de debito deve repetir-se de cada vez que são utilizados novos factores de escala, ou seja o ciclo de débito está inserido no ciclo de distorção. Executa-se este ciclo até que o ruido fique abaixo do limiar de mascaramento para cada banda crítica.
Construção do bitstream: A ultima etapa do processo de codificação consiste em produzir um bitstream de acordo com a norma.
O audio codificado é armazenado em tramas, em conjunto com alguns dados adicionais. Cada uma das tramas contém informação relativa a um bloco de áudio por canal. Uma trama é constituida pelo cabeçalho, dados de áudio e dados opcionais. No cabeçalho de cada trama é descrita, qual a frequência de amostragem, o débito, qual a layer (camada), entre outras coisas. Pode-se optar ou não pela utilização de CRC.
Os dados que são codificados pelo codificador entrópico de Huffman e a sua informação colateral são colocados na parte relativa aos dados de audio, onde a informação colateral vai especificar o tipo de bloco, factores de ganho das sub-bandas e tabelas de Huffman.
META-DADOS
É possivel inserir variada informação nos ficheiros MP3, para além do audio. O formato ID3 é o mais utilizado para guardar essa informação, sendo a versão ID3v2 a versão mais recente. Cada etiqueta ID3v2 é dividida em tramas, cada trama pode incluir variada informação sobre a musica que o ficheiro contém, como por exemplo o artista, título, álbum, letra da música e imagens. Este formato foi desenhado para ser extensível e flexivel, sendo fácil adicionar ao ID3v3 novas funcionalidades. A codificação de caracteres no formato Unicode é suportada. Para que seja eficiente, toda a informação é comprimida. Existe um mecanismo que permite que os leitores que não suportam ID3v2, o ignorem. Normalmente a informação ID3v2 está no inicio do ficheiro, para que seja possivel o seu uso em streamming, contrariamente ao que ocorre na versão ID3v1, cuja informação é armazenada no fim do ficheiro. Existe a possibilidade de que o mesmo ficheiro contenha informação em ambos os formatos (ID3v2 e ID3v1).
DISPOSITIVOS
No inicio, os ficheiros MP3 só podiam ser lidos por programas no computador, como por exemplo o Quicktime ou o Winamp. Pela sua proliferação através da Internet, existiu a necessidade de produção de leitores portáteis do formato MP3. Isto trouxe muitas vantagens, tais como o facto de ter capacidade para uma maior quantidade de musicas, com uma qualidade semelhante e tamanho muito menor que os leitores de CD portateis.
  
Fig 8: Leitores e programa de computador para ler ficheiros MP3
O primeiro leitor de MP3 que surgiu no mercado foi o MPMan F10 da empresa Eiger Labs. O surgimento dos primeiros leitores de MP3 causou conflito pois a industria discográfica impôs pressão no intuito de que estes dispositivos não fossem lançados no mercado. Porém hoje em dia tornou-se banal, tal como os telemóveis a existência de leitores de MP3, com grande variedade de produtos, sendo o iPod um dos mais famosos. Existem diversas capacidades de armazenamento, chegando os mais baratos a custar 20€, alguns já integrando rádio. Hoje em dia os leitores portateis além de lerem ficheiros MP3 tambem têm outras caracteristicas como a possibilidade de armazenamento de dados, visualização de imagem e até video.
|
