CODING
O factor compressăo é preponderante na televisăo 3D, uma vez que o sinal terá de ser emitido e visto em tempo real. No caso do cinema 3D esse problema năo existe, uma vez que o filme esta armazenado.
Para se usufruir da televisăo 3D é necessário, pelo menos, duas vistas (uma para o olhos esquerdo e outra para o direito), bem como proceder ao broadcasting dessas duas vistas. Este factor requer a utilizaçăo do dobro da largura de banda utilizada em televisăo convencional. O aumento abrupto da largura de banda levou ŕ necessidade de um codificador que explorasse a redundância entre as duas vistas para a mesma imagem.
Convencionalmente uma imagem stereo é formada com duas vistas da mesma imagem, estando cada uma dessas vistas deslocada uma da outra no plano horizontal. Tendo em conta que o deslocamento é ténue, é facilmente verificável que de uma imagem para a outra exista muita informaçăo redundante, ŕ imagem da redundância temporal de um vídeo em 2D, sendo assim possível utilizar princípios semelhantes aos utilizados nos primeiros codificadores de vídeo.
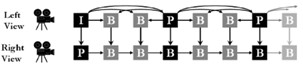
Na norma H.262/MPEG-2 já se contempla a combinaçăo de duas imagens, utilizando a prediçăo entre vistas e a prediçăo temporal (Figura 5).
Figura 5 – Exemplo de prediçăo multivista no H.262/MPEG-2 [6].
Desta forma tem-se compatibilidade directa, visto ser possível apenas descodificar o bitstream do olho esquerdo e mostrar um vídeo 2D para televisores sem tecnologia 3D.
Para televisores 3D é possível explorar a redundância espacial (apenas entre a vista da direita em relaçăo ŕ da esquerda). Embora se ganha eficięncia, quando comparado com a codificaçăo independente dos dois vídeos, esta opçăo é sempre limitada porque năo explora a redundância temporal na imagem da direita.
Para contornar esse problema, na norma lançada em Maio de 2003 o H.264/MPEG-4 AVC já se considera um “Multi View Codding” (MVC) onde se explora a redundância estatística entre vários pontos de vista diferentes bem como a redundância temporal para cada uma das vistas, aborda-se igualmente a construçăo de dois bitstreams distintos, um que suporta um número arbitrário de pontos de vista e outro especificamente criado para duas vistas para o vídeo estereoscópico (3D). Estas extensőes MVC foram apenas acabadas em Novembro de 2009 e estăo especificadas no anexo H do H.264/AVC [7]. Estes bitstreams săo completamente compatíveis com equipamentos anteriores onde novamente se usa apenas uma das imagens. O problema desta combinaçăo de perdiçőes temporal, e entre vistas, como se mostra na Figura 6, é a complexidade. Neste sistema săo necessários, requisitos adicionais de memória e delays adicionais, é preciso ter em conta também que existem condiçőes diferentes de iluminaçăo nas duas câmaras, que irăo afectar a exploraçăo da redundância espacial entre vistas.
A vantagem deste tipo de codificaçăo é que mesmo que a largura de banda de transmissăo desça, o cliente pode apenas descodificar e visualizar um pequeno número de vistas, reduzindo no entanto a qualidade e o número de ângulos de visualizaçăo como se observa na Figura 4 c) – “Narrow view angle”.
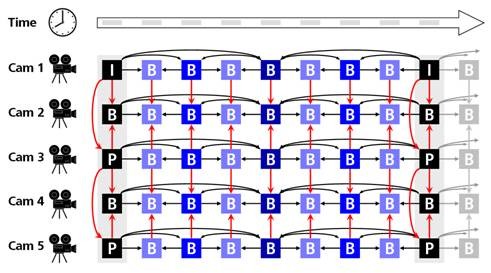
Figura 6 - Estrutura típica de um MVC [8].
2. MVC – codificaçao de VIDEO MULTI-VISTA
A condiçăo para se ter qualquer imagem ou video 3D é haver várias vistas da mesma cena, de forma a posteriormente, criar o produto 3D, independentemente da tecnologia usada.
A soluçăo mais simples para fazer a codificaçăo destas vistas, que originam o objecto 3D seria, partindo do pressuposto que săo necessárias N vistas para a aplicaçăo, codificar independentemente cada uma das N imagens usando para isso, por exemplo um codec como o H.264/AVC. Contudo, ao se ignorar todas as dependęncias estatísticas que cada vista tem com as outras N-1, vários algoritmos MVC foram criados, explorando as varias dependęncias, Figura 6, que levaram a grandes ganhos no factor de compressăo. No entanto, um MVC que explore todo o tipo de redundâncias tem bastante mais complexidade.
Foi demonstrado também que a complexidade diminui drasticamente se a prediçăo entre vistas for restrita a imagens chave, denominadas imagens I REF _Ref262479098 \n \h [9].
3. 2D-3d
A ideia fundamental da conversăo 2D-3D é recriar a visăo binocular humana através de uma única imagem 2D, ou seja, criar a partir de uma imagem denominada original uma outra imagem secundária, ligeiramente diferente da original (estereoscopia), permitindo assim ter uma imagem para cada olho. Para criar uma imagem secundária existem vários métodos, contudo, todos se focam no deslocamento horizontal. Ou seja, a imagem secundária é igual ŕ original mas deslocada horizontalmente.

Figura 7 - Representaçăo de conversăo 2D-3D [20]
O método mais simples denomina-se “cut and paste thecnique”, este método usa a imagem original para o olho esquerdo e com ligeiros deslocamentos horizontais cria uma segunda imagem para o olho direito. É de reforçar que esses deslocamentos năo săo iguais para toda a imagem, é feito um reconhecimento de objectos na imagem e esse deslocamento e independente para cada objecto aumentando com a profundidade do mesmo.
Este método tem como principal desvantagem o facto de ser demasiado lento e pesado quando a imagem contém muitos objectos. Facto que levou a criaçăo dos chamados “depth maps ” (mapas de profundidade).
Os “depth maps” săo imagens que contęm níveis de iluminaçăo da imagem original, sendo estes valores inversamente proporcionais ŕ profundidade. Novas vistas da imagem podem ser criadas usando a original e o seu mapa de profundidade, este processo é denominado DIBR (imagem de profundidade baseada em “rendering”).
Como se pode observar na Figura 8, a imagem do olho esquerdo e a imagem do olho direito nas posiçőes de câmara ci e cr podem ser geradas para uma posiçăo de câmara indicada (t).
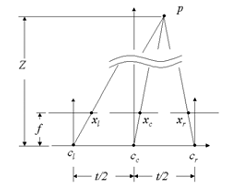
Figura 8 – Configuraçăo de câmara para geraçăo de imagens estereoscópicas [10].
Se for conhecida a profundidade (Z) e a distância focal (f), a extensăo de mudança de pixel pode ser calculada pela relaçăo demonstrada em (1):
![]()
Estes métodos tęm particular interesse para a televisăo 3D pois permite uma transmissăo eficiente em termos de armazenamento, ou seja, um conjunto de imagens e os seus mapas de profundidade respectivos săo mais facilmente comprimidos do que dois (ou mais) streams de imagens utilizados para TV-3D.

Figura 9 – Mapa de profundidade [19]
Mapas de profundidade com duas câmaras