MPEG-1 Layer 3, mais frequentemente conhecido como MP3 é, sem qualquer tipo de dúvida, o formato que domina a transmissão de áudio em formato digital. Assim, é importante analisar detalhadamente as suas características e funcionamento, como forma de tentar descobrir o que o destaca entre todas as outras técnicas de codificação lossy (e losseless !) existentes.
Parece um contra-senso, mas uma das mais importantes propriedades dos standards MPEG (incluindo, obviamente o MP3) prende-se no principio de minimização dos elementos normativos. Assim, e no caso específico da codificação áudio, apenas a representação dos dados e a sua descodificação estão normalizadas. Mesmo a descodificação apenas está especificada em termos das fórmulas necessárias para o algoritmo, enquanto que a codificação é deixada completamente ao critério de quem implementa o standard, existindo apenas alguns exemplos, que podem ou não ser seguidos.
A codificação MP3 baseia-se na análise de um sinal de áudio digital, descomposição deste em padrões matemáticos e comparação destes com os modelos psico acústicos presentes no codificador. Resultante desta comparação são descartados os dados que não estão presentes no modelo, ou seja que, segundo o modelo utilizado, não são relevantes para a experiência acústica subjectiva. O grau de “tolerância”, numa análise simplista, a partir do qual se mantêm ou descartam os dados é baseado no Bit-rate (número bits que devem ser guardados por cada segundo da musica) definido por quem está a fazer o encoding. Segue-se, a esta compressão psico acústica, a codificação Huffman, algo semelhante ao processo de codificação de ficheiros .zip, que será descrita em mais pormenor mais adiante.
Deste processo resulta um ficheiro MP3 composto por uma sequência de frames, sendo cada um destes precedido por um header com informação sobre os dados que se lhe vão seguir. No início do ficheiro MP3 existe também uma secção de dados designados por ID3, que contém informação sobre a musica, como o artista, álbum e ano de gravação da faixa. [1].
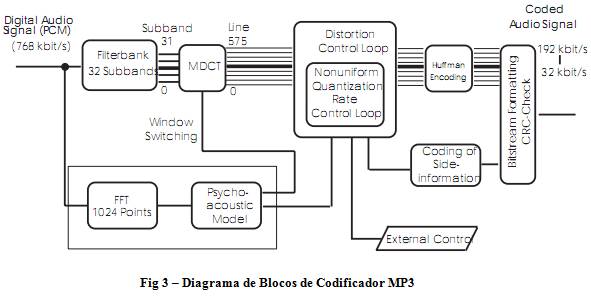
De seguida serão descritos, de uma forma mais aprofundada, os componentes da codificação MP3 presentes no diagrama de blocos da Fig. 3.
Primeira Fase da Compressão Como já foi explicado anteriormente nesta primeira fase recorre-se a estudos psico acústicos, como forma de comprimir o sinal de áudio recebido. Para tal recorre-se a um Banco de Filtros (FilterBanck) híbrido, composto por um banco de filtros polifásico seguido de uma MDCT (Transformada Discreta de Coseno Modificada), e a um modelo psico acústico que, recorrendo ao seu próprio Banco de Filtros, ou combinando-se com os do Banco de Filtros principal. Estes produzem como output um masking threshold ou quantidade de ruído permitida para cada coder partition, que correspondem as bandas de frequência críticas para o ouvido humano. Se o ruído for mantido abaixo deste limite então o resultado obtido deve ser indistinguível do sinal original. [3]
Segunda Fase da Compressão Nesta fase recorre-se, normalmente, a um sistema de dois ciclos de iteração aninhados, efectuando-se a quantificação (processo através do qual é possível aproximar um leque variado de valores através de um número reduzido de símbolos discretos ou valores inteiros) e posterior codificação de Huffman. A codificação de Huffman, por sua vez, recorre às probabilidades de ocorrência de símbolos num conjunto de dados para determinar códigos de tamanho variável para cada símbolo. Assim, e uma vez que é necessário manter o ruído provocado pelo processo de quantificação abaixo dos limites definidos na primeira fase de compressão esta segunda fase é composta por dois ciclos. No primeiro (denominado Inner Iteration loop ou Rate Loop) recorre-se à codificação de Huffman para reduzir o tamanho dos valores quantificados, repetindo-se o ciclo caso o numero de bits obtido exceda o espaço disponível para o bloco de dados. No segundo ciclo (denominado Outer Iteration Loop ou Noise Control Loop) é ajustado o valor de cada banda até que o sinal obtido respeite o masking threshold.