![]()
![]()
![]()
MPEG-2 Advanced Audio Coding (AAC) é um esquema standardizado, com perdas, para codificação de áudio digital. O AAC foi desenvolvido com a cooperação e contribuição de várias companhias entre as quais estão a Dolby, Fraunhofer (FhG), Sony e Nokia, e foi internacionalmente standardizado pela MPEG em 1997. Mais tarde surge então o MPEG-4 AAC, que é essencialmente o MPEG-2 AAC mas com algumas melhorias e novas ferramentas.
Foi inicialmente desenvolvido com o objectivo de atingir uma maior qualidade que o anteriormente criado MP3. O AAC segue essencialmente os mesmos padrões base de codificação que o MPEG-1 Layer III, mas usa novas ferramentas de codificação de forma a conseguir taxas de transmissão mais baixas mantendo a qualidade.
Esta norma explora duas estratégias primárias de codificação para poder reduzir de forma substancial a quantidade de dados necessária para representar áudio digital de alta qualidade. A primeira estratégia consiste em rejeitar componentes do sinal que são perceptualmente irrelevantes. A segunda consiste na eliminação de redundâncias no sinal áudio codificado.
Uma vez que se trata de um codificador perceptual, a estrutura base de um codificador AAC é a apresentada na Figura 5.
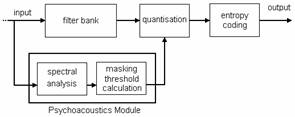
Figura 5 – Estrutura básica de um codificador áudio perceptual.
No entanto, para o AAC, existe ainda um bloco de processamento espectral antes da quantização. Este bloco é usado com o intuito de reduzir a redundância, e consiste sobretudo num conjunto de ferramentas de predição. O esquema completo de um codificador AAC é apresentado na Figura 6.
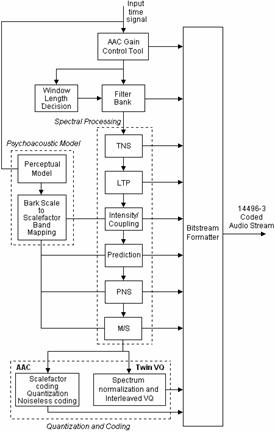
Figura 6 – Diagrama de blocos do MPEG4-AAC.
Assim, uma vez que a codificação de áudio segundo a norma AAC se faz de forma modular, dependendo da complexidade do fragmento de áudio a codificar e da qualidade final desejada é possível definir vários perfis de codificação. Cada perfil define então qual o conjunto de ferramentas a ser utilizado para cada tipo de aplicação. A norma AAC permite quatro modos de funcionamento independentes:
· Main Profile – todas as ferramentas disponíveis são utilizadas, permitindo atingir uma qualidade elevada. Requer muita memória e capacidade de processamento.
· Low Complexity – é o mais simples e o mais usado. Com o propósito de diminuir substancialmente o uso de processamento e RAM, a qualidade final é sacrificada e a taxa de compressão diminui.
· Scaleable Sample Rate Profile – é o modo com menor complexidade, tendo a possibilidade de se adaptar a diversas larguras de banda.
· Long Term Prediction – é um aperfeiçoamento do Main Profile. Utiliza forward predition com baixa complexidade computacional.
No banco de filtros para o Main Profile e para o Low Complexity Profile é utilizada a Transformada Discreta de Co-seno Modificada (MDCT) e no Scaleable Sample Rate Profile é usado um banco de filtros híbrido. A MDCT permite usar diferentes tamanhos de blocos de janela consoante o sinal seja estacionário ou transitório. Quando o sinal muda ou ocorre uma transição, é usado um conjunto de blocos de janela mais pequenos. Este facto permite combater o artefacto de pré-eco a que os codificadores perceptuais são propensos. Caso o sinal seja estacionário, é usada uma janela de maior tamanho. Esta janela maior tem a vantagem de possibilitar um modelo psicoacústico melhor, pois tem uma maior resolução espectral, o que permite obter uma maior eficiência na codificação.
O bloco TNS (temporal noise shaping) também é usado na redução do artefacto de pré-eco, controlando a forma de onda temporal do ruído de quantização. Para tal é utilizada predição no domínio da frequência.
O bloco LTP (Long Term Prediction), que foi adicionado no MPEG-4, é uma ferramenta eficiente na redução de redundância entre sucessivas frames de codificação.
Os blocos Intensity/Coupling e M/S fazem parte da ferramenta Joint Channel Coding Tool.
O Intesity Stereo é um modo eficiente de codificar informação stereo. Em vez de codificar dois canais separadamente, eles são combinados de forma a se obter um stream de áudio mono e uma posição stereo. Os coeficientes espectrais são divididos em blocos contíguos, a cada qual corresponde uma posição stereo.
O Coupling permite que os dados de um canal sejam combinados com os dados do outro canal.
A ferramenta de codificação stereo M/S transforma os canais left e right nos canais mid e side. Os canais mid e side são a soma e a diferença dos canais left e right, respectivamente. Esta ferramenta, ao contrário da Intesity Stereo, mantém inalterado o áudio, não introduzindo qualquer tipo de artefacto no sinal.
A ferramenta de predição (Prediction) emprega pré-predição adaptativa (backward-adaptative prediction) de forma a remover redundâncias contidas em blocos de áudio sucessivos. É apenas aplicada a blocos longos, uma vez que tem um melhor desempenho em sinais estacionários.
Adicionado no MPEG-4, o bloco PNS (Perceptual Noise Substitution) tem como objectivo a optimização de eficiência das taxas de transmissão do AAC, quando estas são baixas. A técnica utilizada no PNS assenta no facto de todos os ruídos “soarem” ao mesmo. Assim, em vez de se transmitir todas as componentes espectrais de um sinal com ruído, é apenas indicado que uma dada região de frequência possui ruído e dar alguma informação adicional sobre a potência total nessa banda.
O quantizador quantiza os dados de forma a que o ruído quantizado seja definido de acordo com o modelo psicoacústico, e seja, ou completamente mascarado ou fique muito pouco perceptível (dependendo das taxas de transmissão). Trata-se de um quantizador não uniforme, ou seja, existe um buffer que permite que se distribua o número de bits a usar em blocos adjacentes de forma não uniforme. Outro aspecto importante é o número limite de bits por frame. Assim existe um processo iterativo no qual é feita a ponderação entre a eliminação de ruído e o número de bits utilizado. Também a codificação de Huffman é utilizada para a codificação espectral sem ruído.
Finalmente, no Bitstream Formatter são agregados os coeficientes quantizados e codificados e os parâmetros de controlo num stream de áudio para transmissão. Este stream é composto por frames de diferentes tamanhos, dependendo das variações causadas pela codificação de Huffman adaptativa.
A Figura 7 ilustra a demanda computacional de um codificador standard de AAC a trabalhar no modo Low Complexity (que é o modo mais comum e mais usado), a codificar a 64 kbps com frequência de amostragem de 44,1 kHz (qualidade CD). Observa-se que os dois módulos mais exigentes a nível computacional são o módulo psicoacústico e o módulo de quantização. Com efeito, são estes os dois módulos que têm vindo a ser mais estudados com vista à sua optimização e à consequente optimização do codificador.
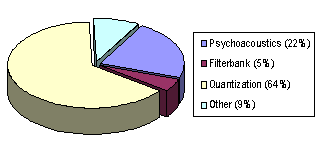
Figura 7 – Distribuição dos recursos num codificador AAC-LC.
![]()
![]()
![]()