
2. Codificação áudio em MP3
Os principais objectivos de codificação de áudio para o standard MPEG1 foram os seguintes [1]:
- Codificação de sinais de um (mono) ou dois canais (estéreo);
- Acesso aleatório (possibilidade de iniciar reprodução em qualquer ponto);
- Baixo atraso de reprodução;
- Bitrate de cerca de 300kbit/s ou menor;
- Diferentes níveis de complexidade, adaptáveis a cada aplicação.
A codificação multi-canal pode ser feita de um de quatro modos [2]:
- Mono – um único canal
- Dual Channel – dois canais não correlacionados, como por exemplo duas versões em línguas diferentes.
- Stereo – sinal áudio com dois canais estereofónicos codificados independentemente.
- Joint Stereo – sinal áudio com dois canais estereofónicos, codificados explorando as redundâncias estereofónicas (especificamente, elimina a precisão estéreo acima dos 2kHz).
Como forma de cumprir os dois objectivos de acesso aleatório e atraso de reprodução, o sinal áudio é dividido em frames. Cada frame poderá ser descodificada de forma independente e terá de ser precedida por um cabeçalho contendo a informação necessária à descodificação.
O sinal áudio correspondente a cada frame pode ser codificado de uma de 3 formas, de complexidade crescente: as layers (camadas). As duas primeiras layers baseiam-se na codificação em frequência do sinal, dividindo-o em 32 gamas de frequência (sub-bandas) e atribuindo um coeficiente a cada uma; na Layer I, estes são computados sobre cada 384 amostras temporais, permitindo menor atraso e complexidade que a Layer II, que usa 1152 amostras. A estrutura simplificada da Layer I implica, no entanto, factores de compressão mais limitados.
A Layer III, objecto deste estudo, adiciona duas características muito importantes ao nível do bitstream.
- MDCT – Efectua uma transformação MDCT (Modified Discrete Cosine Transform) sobre os coeficientes de cada sub-banda. Desta forma, cada bloco temporal de sinal é dividido em 576 componentes de frequência. Ao obter-se uma maior resolução de frequência, permite-se ao codificador maior precisão na codificação perceptual, e consequentemente maiores factores de compressão para a mesma qualidade percepcionada. Esta técnica pode produzir pré-ecos; para evitar este artefacto, a MDCT pode ser efectuada sobre janelas de 6 ou 18 pontos (janela dinâmica).
- Codificação de Huffman – Os coeficientes resultantes da MDCT são codificados pelo método de Huffman, definido numa de 32 tabelas disponíveis.
- Codificação Mono/Stereo – opcionalmente, pode-se codificar os sinais (L+R) e (L-R) em vez de codificar L e R directamente. Esta aproximação explora redundâncias entre os dois canais e ganha bitrate na quantização do canal (L-R), usualmente com menor intensidade. Pode ser usado em conjunto com o modo Joint Stereo.
Para todas as camadas, obtém-se compressão ao quantizar os coeficientes durante a codificação. O codificador, e consequentemente a estratégia de quantização, não são impostos pelo standard. No entanto, é severamente limitada pelo bitstream definido e recomenda-se o uso de codificação perceptual.
2.1. Codificação perceptual
Os formatos de áudio definidos no MPEG1 foram dos primeiros a fazer uso de técnicas perceptuais de codificação de áudio. A codificação perceptual procura explorar as limitações do sistema auditivo humano. Os fenómenos auditivos explorados pelo MP3 são:
- Limiar de audibilidade em silêncio – Para cada frequência, o ser humano ouve apenas sinais com amplitude acima de um determinado limiar, mesmo se não houver energia nas restantes frequências (Figura 1)
- Mascaramento em frequência – Um sinal forte numa determinada frequência torna inaudíveis sinais fracos em frequências próximas (Figura 1)
- Mascaramento temporal – Um sinal forte num dado instante torna inaudíveis sinais fracos em janelas temporais imediatamente anteriores (pré-mascaremento) ou posteriores (pós-mascaramento) (Figura 2).
Um codificador mp3 que faça uso de codificação perceptual analisa o sinal áudio para computar um limiar de mascaramento (Figura 1), que define para cada frequência a amplitude abaixo do qual um sinal é inaudível. Este permite:
- Descartar coeficientes correspondentes a sinais abaixo deste limiar; elimina coeficientes irrelevantes.
- Quantizar os restantes sinais com o mínimo de bits que mantenha o ruído resultante da quantificação esteja do limiar (seja inaudível); elimina precisão desnecessária.
Desta forma elimina-se a informação irrelevante, construindo um sinal que é perceptivelmente idêntico ao original, mas que pode ser descrito com menos bits.
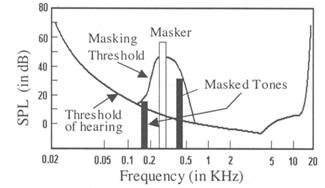
Figura 1 – Limiar de audibilidade em silêncio (Threshold of hearing) e mascaramento em frequência. O sinal mascarador (masker) define um limiar de mascaramento (masking threshold). Sinais abaixo deste limiar (masked tones) podem ser descartados. (Fonte: [4])
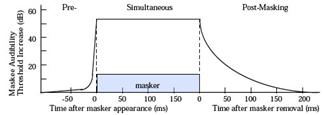
Figura 2 – Mascaramento temporal. Um sinal pode mascarar outros imediatamente anteriores e/ou posteriores a ele mesmo. (Fonte: [5])
A Figura 3 apresenta uma arquitectura de codificador que faz uso de codificação perceptual, bem como a de um descodificador normativo.
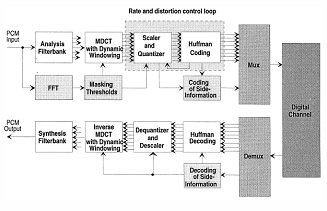
Figura 3 – Arquitectura-tipo de codificador e descodificador MP3. Todos os blocos excepto os de MDCT e codificação Huffman são partilhados pelas 3 camadas. É importante notar que o codificador não é definido na norma. (Fonte: [6])
2.2. Qualidade do MP3
A codificação de um sinal MP3 pode implicar perdas de qualidade perceptíveis, especialmente quando se codifica para bitrates baixas [1]. Verificam-se:
- Pré-ecos – O ruído de quantização é imposto sobre um coeficiente de componente de frequência. No domínio do tempo, este erro está espalhado sobre todo o frame em causa. Assim, e especialmente no caso de transições temporais súbitas (um som de castanholas, por exemplo), pode-se ouvir ruído significativo mesmo antes do evento que o causa (Figura 4). Como forma de evitar este efeito, a MDCT pode utilizar janelas de 6 ou de 18 pontos. A janela de 6 pontos sacrifica resolução de frequência para ganhar resolução temporal e deve ser utilizada quando o modelo perceptual detecta a possibilidade de pré-eco. O pós-eco, artifício análogo, é normalmente inaudível devido ao pós-mascaramento.
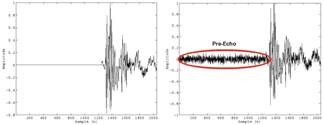
Figura 4 – Pré-eco. Uma transição abrupta pode provocar ruído de quantização espalhado por toda a janela temporal descrita pelos coeficientes MDCT.
- Ruído de quantização – O ruído de quantização introduzido no codificador é muito diferente do ruído presente nos meios de armazenamento e comunicação anteriores. Trata-se de um ruído não-branco, pois é diferente para cada componente de frequência, e variante no tempo, pois é diferente em cada frame.
- Perda de largura de banda – Ao não conseguir cumprir a bitrate pedida, um codificador pode apagar componentes de frequência, normalmente as correspondentes às frequências mais elevadas. De novo, o erro introduzido é variante no tempo (diferente em cada frame).
Em geral, as perdas de qualidade introduzidas são perceptivelmente diferentes das presentes em métodos de armazenamento analógicos, como vinil ou fita magnética, e até no CD áudio. Este facto levou a uma baixa adopção do formato por audiófilos; no entanto, foi provado que novas gerações de ouvintes acabam por preferir o ruído do MP3, possivelmente por uma questão de hábito [8].
REFERÊNCIAS
- http://www.faqs.org/faqs/mpeg-faq/part1/ as of May 2009.
- Brandenburg, “MP3 and AAC explained”, AES 17th International Conference on High Quality Audio Coding
- Peter Noll, “MPEG Digital Audio Coding Standards.”, 2000, CRC Press LLC. http://www.engnetbase.com
- http://cs.uccs.edu/~cs525/audio/audio.html .
- http://www-scf.usc.edu/~ise575/b/projects/cheng/
- "MPEG Digital Audio Coding”, in IEEE Signal Processing Magazin, September 1997.
- Nick Spence, “Computer Generation Prefers MP3 fidelity to CD”, [Online] in Computer Dealer News, 3/5/2009, http://www.itbusiness.ca/it/client/en/cdn/News.asp?id=52299
- iPod generation prefer MP3 fidelity to CD, http://www.itbusiness.ca/it/client/en/cdn/News.asp?id=52299
- MPEG-FAQ: Multimedia Compression, http://www.faqs.org/faqs/mpeg-faq/part1/