As principais oportunidades para a redução do débito binário [1] associado à representação PCM de sinais áudio são:
- a redundância temporal ou simplesmente redundância
- a redundância perceptiva ou irrelevância
- a redundância estatística
A redundância temporal consiste num sinal ter amostras em diferentes momentos no tempo com igual ou muito semelhante valor, nesse caso tais amostras poderão ser descritas de uma forma mais simples, gastando desse modo menos bits.
No que toca à redundância perceptiva, ela tem um papel preponderante no que toca ao áudio, uma vez que é explorando tal redundância que se conseguem melhores taxas de compressão. Esta tem o papel de eliminar partes do sinal que não são perceptíveis pelo ser humano baseando-se num modelo do aparelho auditivo humano, modelo psicoacústico. Tal, tanto pode ser efectuado no domínio do tempo como no domínio da transformada, é habitual neste caso falar-se também em codificação por transformada. Este método provoca uma mudança do espaço de representação do sinal, através de uma fórmula matemática, tornando assim evidentes determinadas caracteristicas que facilitem a sua codificação. A transformada frequentemente utilizada em compressão de áudio e vídeo é a DCT (discrete cosine tranform), mais particularmente no áudio utiliza-se a MDCT (modified discrete cosine tranform).
Por fim, a redundância estatística consiste em identificar os símbolos de informação que ocorrem com maior frequência, de modo a dar-lhes uma palavra de código mais curta em relação aos símbolos menos frequentes, aos quais é atribuída uma palavra de código maior.
As três ferramentas apresentadas anteriormente são a base daquilo que existe para se poder comprimir um sinal digital no geral, particularmente de áudio. Das três, daremos principal destaque à redundância perceptiva, pois sendo a maior responsável para o aumento da taxa de compressão é a que apresenta maiores desafios a nível técnico, esta assenta basicamente na actuação conjunta do modelo psicoacústico com o quantizador.
Psicoacustica
A psicoacústica é o estudo da percepção humana do som. O som que nos chega aos ouvidos sob a forma de uma onde mecânica é aí transformado num sinal electroquímico, este é transportado até ao cérebro e aí é percepcionado. Compreendendo bem todo este processo, do tratamento do sinal sonoro por parte do aparelho auditivo, é possível tirar partido das suas limitações. Para tal, desenvolvem-se modelos psicoacústicos que maximizam a poupança de palavras de código sem que isso seja perceptível.
As principais limitações exploradas prendem-se com a sensibilidade do ouvido humano e com o efeito de mascaramento.
No que toca à sensibilidade, a figura 1 mostra a curva que representa o valor da intensidade sonora a partir da qual o som é audível ao longo da frequência.
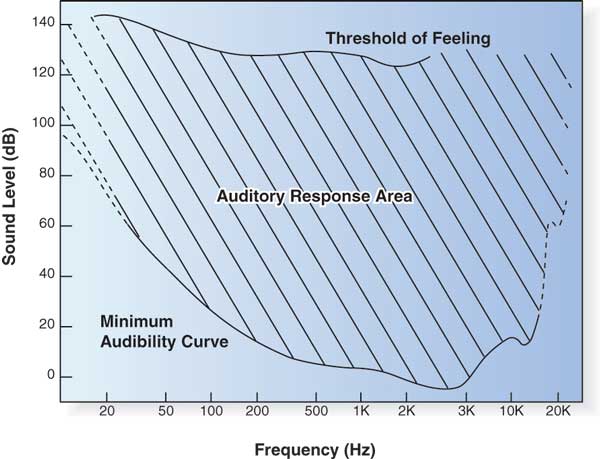
Figura 1: Sensibilidade do ouvido humano.
Como é visível no gráfico, para frequências inferiores a 100 Hz e superiores a 10 kHz o ouvido perde rapidamente a sensibilidade, sendo que abaixo dos 20 Hz e acima dos 20 kHz já não é possível ouvir; este limite deteriora-se rapidamente com a idade, sendo que um humano na idade adulta não ouve acima dos 16 kHz; este facto é frequentemente considerado para obter melhores taxas de compressão. No que toca à intensidade, temos a capacidade de ouvir sons até cerca dos 130 dB, limiar este ao qual se dá o nome de limiar da dor.
Em relação ao mascaramento, é o fenómeno que acontece quando um som, o mascarante, se sobrepõe a outro, o mascarado, tornando-o parcialmente ou completamente inaudível. Tal influência é função da relação temporal, da intensidade e frequência entre os dois sons. Existem dois tipos de mascaramento: simultâneo e não simultâneo ou temporal.
O princípio do mascaramento simultâneo [2] está ilustrado na figura 2. Este acontece quando dois sons apresentam frequências próximas, nesse caso o som com maior intensidade tende a mascarar o segundo, provocando uma alteração no traçado da curva da sensibilidade auditiva que o torna inaudível. Este efeito, simulado pelo modelo psicoacústico, faz com que seja possível inserir ruído no sinal, nomeadamente reduzindo o passo de quantificação, na gama de frequências que o som mascarante torna inaudível.
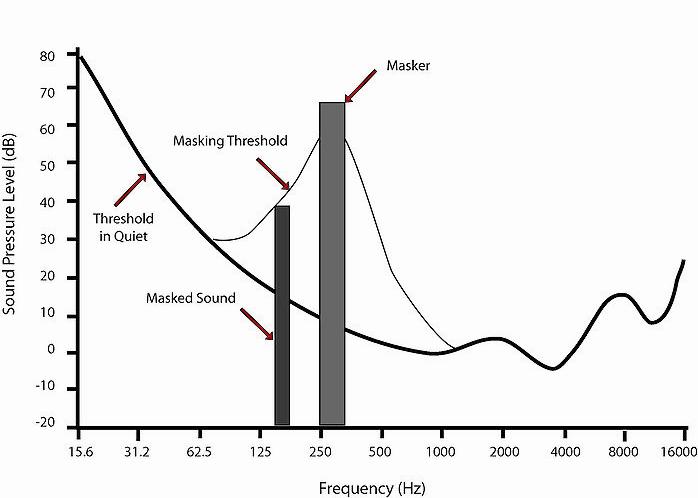
Figura 2: Mascaramento temporal.
Em relação ao mascaramente temporal, acontece quando subitamente um estimulo sonoro repentino torna inaudível outros sons que eram audíveis. Estando o ouvido habituado a uma dada intensidade sonora, um aumento brusco na intensidade provoca esse efeito, em seguida o ouvido leva algum tempo até recuperar a audição das intensidades sonoras mais baixas. Este efeito é comparável ao da saída de uma discoteca onde a intensidade sonora é elevada, o ouvido leva posteriormente algum tempo até recuperar a sensibilidade por exemplo ao nível de intensidade da fala.
Modelo Genérico de Compressor de Áudio
Após apresentadas as principais ferramentas de codificação de áudio, apresenta-se agora considerações concretas sobre a estrutura genérica de um compressor. Na figura seguinte encontra-se o diagrama do respectivo modelo.
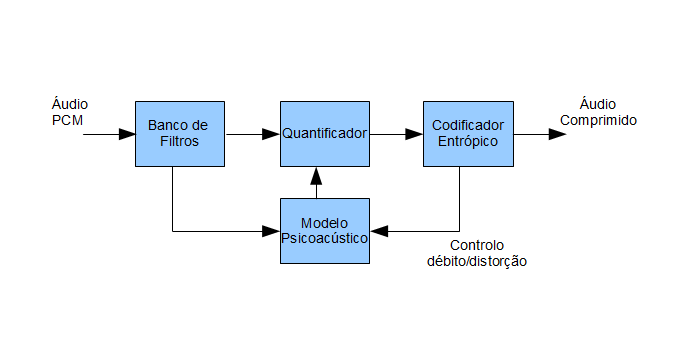
Figura 3: Diagrama de blocos simplificado do modelo genérico de codificador de áudio.
Como podemos ver no diagrama parte destes módulos já foram referidos. Nomeadamente, o papel do modelo psicoacústico que em conjunto com o quantizador é responsável por injectar ruído, poupando bits, tirando partido das oportunidades de mascaramento simultâneo e temporal. Em relação ao banco de filtros, tem a função de decompor o sinal na frequência, permitindo moldar o ruído de quantificação de acordo com a oportunidades de cada faixa de frequências. O número de filtros utilizados está relacionado com o tipo de sinal de áudio que se pretende comprimir. Ainda a referir há a rotina de controlo débito/distorção, que basicamente tem como objectivo optimizar o ruído de quantização face ao débito binário desejado.
|