Questões Técnicas
Antes de prosseguir com a descrição das técnicas usadas para obter o formato mp3, é essencial contextualizar o seu aparecimento e explicar que tipo de necessidades visava responder.
Uma das principais motivações que levou ao
desenvolvimento desta norma foi o aparecimento de suportes de
gravação digital, com grande capacidade e elevadas velocidades de
leitura. Nesta altura, década de 90, eram vários os possíveis:
CD-ROM, CD-WORM, discos Winchester, DAT, … De entre todos, o CD-ROM
foi escolhido como o mais adequado para oferecer, em larga escala,
sinais multimédia interactivos, sobretudo devido à sua elevada
capacidade e baixo custo.
 Assim
sendo, tendo como principal objectivo a gravação digital de vídeo em
CD-ROM, a norma MPEG1 foi optimizada para débitos totais (áudio e
vídeo) de, aproximadamente, 1.5 Mbit/s
Assim
sendo, tendo como principal objectivo a gravação digital de vídeo em
CD-ROM, a norma MPEG1 foi optimizada para débitos totais (áudio e
vídeo) de, aproximadamente, 1.5 Mbit/s

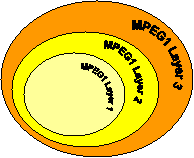
As três normas possíveis de áudio em MPEG1 são como que 3 camadas, que representam diferentes compromissos débito/qualidade/complexidade/atraso. Assim a camada exterior, o MPEG1 Layer3 (o MP3!!), é aquela que tem maior complexidade, eficiência de compressão e atraso.
De forma muito resumida, pode definir-se um codificador como uma cadeia de processos matemáticos, pelo que um codificador perceptivo pode ser representado da seguinte forma:
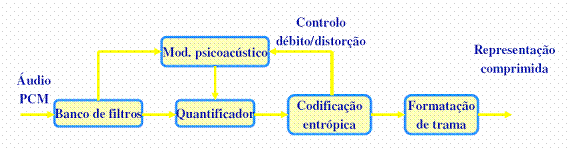
É importante referir que, tanto o MP1, como o MP2 ou o MP3 usam o modelo psico acústico para melhor comprimir áudio. O que distingue o MP3 do dos restantes é a granularidade de acção, ou seja, à custa de maior complexidade o MP3 consegue analisar o áudio com mais pormenor.
MODELO PSICO ACÚSTICO
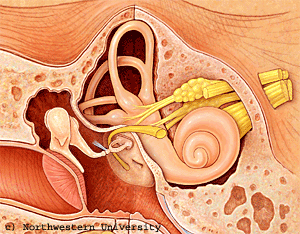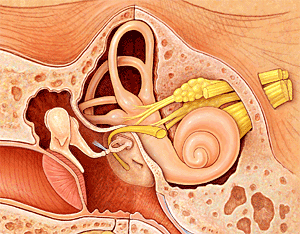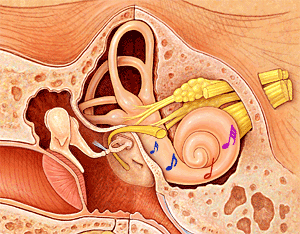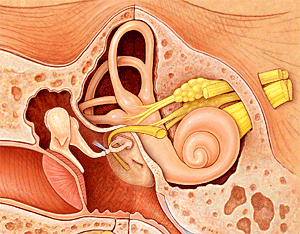
O modelo psico acústico é um modelo matemático que tenta representar, o melhor possível, as capacidades auditivas humanas, ou seja, a sensibilidade do ouvido humano, nomeadamente em relação à intensidade sonora, à selectividade espectral e ao efeito do “mascaramento”.
Ter um modelo que permita saber o que é que realmente ouvimos é de uma utilidade extrema, porque, além de permitir “descartar” do sinal tudo o que nos é irrelevante, permite injectar erro de codificação nessas zonas, o que obviamente resulta na diminuição do débito associado ao sinal codificado.
Numa primeira análise o modelo começa por definir um limiar para o que ouvimos, ou seja, começa por definir a intensidade mínima do som para ser ouvido. Esta intensidade mínima varia ao longo da banda de um sinal de voz, que se situa entre os 0 e 4 kHz.
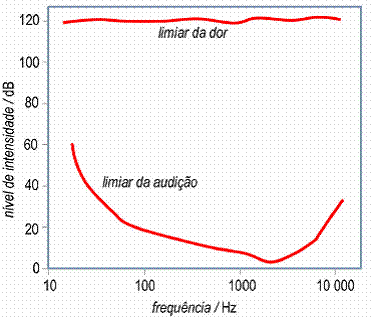
Posto isto, pode dizer-se que, o mascaramento altera os limiares de audição, e podem definir-se 2 tipos distintos:
· Mascaramento na frequência;
· Mascaramento no tempo;
MASCARAMENTO NA FREQUÊNCIA
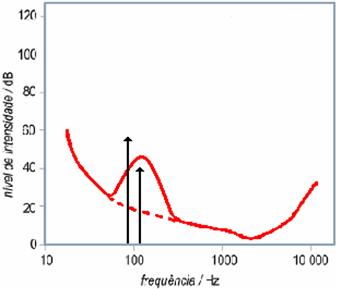
A largura da mascara não é independente dá
frequência do som que a provoca. De facto, a largura da mascara
aumenta com a frequência.
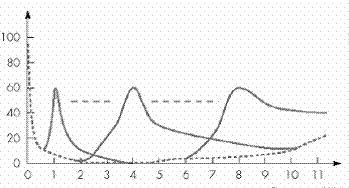
Estas diferentes larguras de mascara são designadas de bandas críticas. De momento podem definir-se 3 bandas de frequência críticas:
· f»500Hz, com LB=100Hz;
· f»1kHz (2x500Hz), com LB=200Hz (2x100Hz);
· f»5kH (10x500Hx), com LB=1000Hz (10x100Hz);
A forma destas bandas tem sido muito estudada, para se conseguir um modelo cada vez mais fiel do sistema auditivo humano.
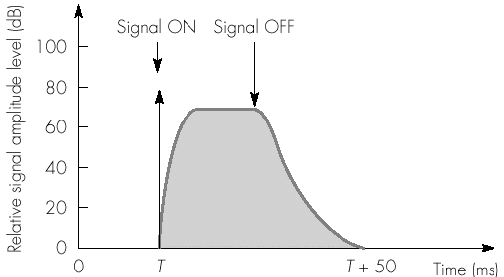
Os sons que não conseguem ser detectados pelo ouvido humano devido ao mascaramento (área a cinzento do gráfico) não precisam, portanto, de fazer parte do sinal depois de codificado.
Como se pode ver, é extremamente importante ter
bem definidos os sinais importantes ao ser humano e os não
importantes, umas vez que enviar sinais irrelevantes representa
“desperdício” de bits, quando o objectivo principal é compressão
máxima.
A principal função do modelo psico acústico, enquanto parte integrante da arquitectura de um codificador perceptivo, é controlar o erro que quantificação a introduzir em cada banda.
BANCO DE FILTROS
O “Banco de filtros” é a primeira etapa do processo de “transformação” de um sinal PCM. O sinal PCM representa amostras de áudio no domínio do tempo. Como é fácil perceber, para poder explorar toda a redundância e irrelevância de um sinal áudio, faz sentido analisa-lo, também, no domínio da frequência. É essa a função do banco de filtros: decompor o sinal em sub-bandas de frequência, passando a descreve-lo no domínio tempo/frequência.
O codificador MPEG1 Layer3 utiliza uma estrutura de codificação tempo/frequência híbrida, ou seja, recorre aos dois tipos de codificação na frequência possíveis:
Codificação por sub-bandas (também usado pelas Layers 1 e 2), e Codificação de transformada (Modified DCT).
O codificador MP3 consegue usufruir destas duas técnicas dispondo-as em “cascata”, ou seja, primeiro faz a codificação por sub-bandas e depois aplica a Modified DCT a cada uma das bandas resultantes, tal como está explícito na figura:
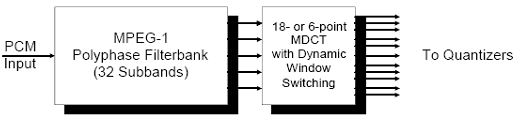
Codificação por sub-bandas
Como é fácil perceber, a codificação por sub-bandas consiste em decompor um bloco de amostras em vários sub-conjuntos de amostras, usando filtros passa-banda (32 neste caso), contínuos na frequência, de forma que o conjunto final das várias bandas possa ser recombinado aditivamente para sintetizar o sinal original.
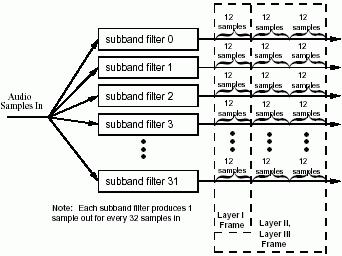
Esta figura, além de exemplificar o funcionamento de um banco de 32 filtros passa-banda, mostra a evolução da Layer 1 para as Layers 2 e 3. O facto das Layers 2 e 3 usarem 36 amostras, em vez de 12, permite-lhes que explorar redundância entre scale factors dos 3 grupos (3x12 amostras). Só o facto de se explorar a redundância, permite aos Layers 2 e 3 obter o dobro da compressão em relação ao Layer 1.
Codificação de tranformada.
O MP3 tenta compensar algumas das falhas do banco de filtros, característico das Layers 1 e 2, recorrendo à codificação de transformada.
Uma transformada é, neste contexto, um procedimento matemático que permite converter um bloco de amostras estatisticamente dependentes, num bloco de coeficientes quase independentes onde a energia se encontra normalmente concentrada numa pequena parte dos coeficientes. caracterizar um sinal no domínio da frequência. A DCT é a mais popular no mundo da codificação de imagem, sendo usada nas mais diversas normas. No entanto, a DCT não é a mais indicada para codificação de áudio, uma vez que, a audição humana é mais sensível ao “efeito bloco” do que a visão. Assim, na codificação de áudio, utiliza-se a DCT Modificada (MDCT), que alem de diminuir o “efeito bloco”, com a sobreposição de janelas, permite evitar o efeito “pré-eco”, com a comutação de janelas.
O efeito pré-eco nota-se quando, em vez de silêncio, se ouve um ruído de fundo antes de um som. Por exemplo, antes de uma faixa de música. Isto acontece, quando a “janela de amostras” que vem do banco de 32 filtros para o codificador de transformada engloba essa transição, uma vez que a transformada é aplicada à totalidade da amostra, podendo alterar a parte do silêncio. Este efeito pode ser atenuado com o uso janelas de amostras com tamanhos variáveis consoante o sinal a codificar (comutação de janelas).
Assim, com a aplicação da MDCT, as 32 sub-bandas são sub-divididas em 6 ou 18 coeficientes, conforme haja ou não efeito pré-eco previsível.
QUANTIFICADOR
Quer isto dizer que, a quantificação dos coeficientes MDCT, através da alocação de bits, se baseia nos limiares de audição dados pelo modelo psico-acustico, podendo introduzir erro (e consequentemente gastar menos bits) nas frequências em que somos menos sensíveis.
É importante perceber, que é aqui, no processo que quantificação, que são introduzidas “perdas” de informação irrecuperáveis, o que faz do MP3 um método de codificação “com perdas”.
Normalmente, é usado no MP3 um mecanismo com dois ciclos aninhados para quantificação e codificação.
CODIFICAÇÃO ENTROPICA
Este tipo de codificação permite uma redução de bits no resultado final na ordem dos 20%.
FORMAÇÃO DA TRAMA
É nesta fase do processo de codificação, que se percebe a importância da existência de uma Norma que garanta interoperabilidade entre os vários descodificadores. Assim a trama resultante do processo de codificação deve respeitar as especificações dadas pela norma MPEG 1 Layer3.