Descrição e Procura de Música
Arquitectura do Sistema
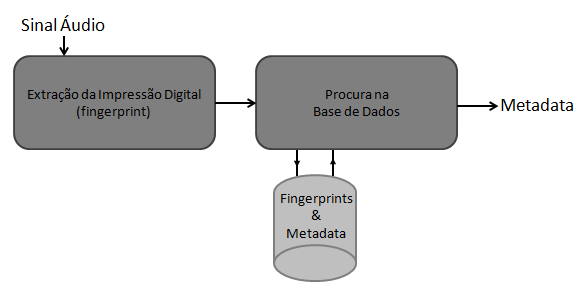
Extracção da Impressão Digital
O extractor da impressão digital deverá tentar reduzir ao máximo a dimensão da amostra, mantendo apenas os parâmetros característicos do objecto áudio. Limpando o mesmo de distorções e ruídos a que este foi sujeito. Para tal, deverá então usar a dinâmica espectral do sinal como principal elemento de correlação ao invés das suas características.
Primeiro dever-se-á proceder a uma digitalização do sinal para um formato de carácter geral como é o formato PCM.
Seguidamente, dividindo o sinal em pequenos frames de tamanho suficientemente pequeno para que se possa considerar que as alterações acústicas dentro do mesmo podem ser desesperadas, de uma forma geral, a maioria dos autores entende que estas janelas temporais devem ter um comprimento de 300ms. Para dar robustez ao código contra problemas de sincronismo do sinal observou-se que as várias amostras temporais deveriam estar bastante relacionadas entre si, estando para isso sobrepostas num mínimo de 50%, tomaremos agora em conta a abordagem de Avery Wang[15], [11] que considera que existem 11,8ms de amostra entre cada sobreposição o que gera um factor de sobreposição de 31/32.
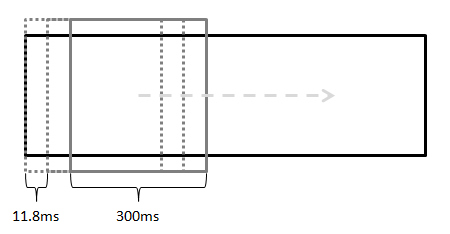
Neste caso e considerando, tal como Avery Wang no seu algoritmo, que são precisos apenas 3 segundos de granularidade, consegue-se perceber que o algoritmo trabalhará em cada momento com cerca de 256 frames temporais, intimamente correlacionados, devido à sua sobreposição.
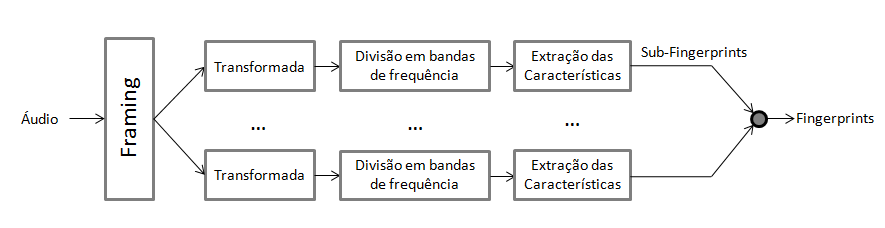
É então chegada a altura de transformar cada frame utilizando transformadas lineares. Transformadas como a Karhunen-Loève ou a Singular Value Decompositon seriam óptimas, no entanto, como dependem do sinal em análise os autores acabaram por dar preferência a transformadas lineares como a Transformada Rápida de Fourier (FFT), a Discrite Cosine Transform, a Haar Transform ou a Walsh-Hadamard Transform.
O sinal é então tratado para lhe serem extraídas as características que o vão distinguir de todos os outros sinais. Estas características são depois processadas de forma a normalizar todas as amostras. É neste ponto que os vários autores mais divergem, uma vez que é também aqui que a força do algoritmo encontra a sua maior arma, pois a escolha das características correctas levará ao algoritmo perfeito, enquanto que a escolha errada das características poderá empurrar o algoritmo para o insucesso.
É importante relembrar que é importante que o algoritmo que gera as impressões digitais não gere uma impressão digital completamente diferente caso o sinal venha perturbado por ruído, pois isso dificultaria muito a procura da música na base de dados do sistema.
Exemplo Simples de Implementação
Tomando como exemplo a aplicação da FFT, o algoritmo consegue traçar o espectrograma de picos de intensidade espectral do sinal, fornecendo assim ao bloco de extracção das características um mapa da distribuição da energia no tempo e na frequência. Por pico de sinal considera-se todo o sinal que tem o valor máximo da sua vizinhança. Sendo que o valor de comprimento temporal da vizinhança é uma especificação do algoritmo. Desta forma, ignoram-se os picos secundários que muitas vezes são fruto das distorções sofridas pelo sinal. Correspondendo muito raramente a notas distintas ou padrões de ritmo das melodias.
É de notar que os algoritmos tendem a eliminar todas as gamas de frequências fora da gama a que o ouvido humano é sensível. Os algoritmos desenhados para fazer a análise de sinais processados por telefones móveis vão mais longe rejeitando toda a gama de frequências fora da gama de frequência de voz do ser humano, uma vez que o sinal que vão receber também estará processado segundo esse pressuposto.
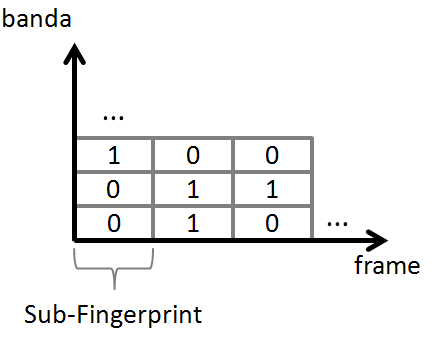
Para facilitar a análise a janela de frequência é comummente dividida em 33 sub-bandas distintas (e não sobrepostas). É então explorada a dinâmica destes picos de magnitude do sinal, tanto na frequência como no tempo.
De uma forma sucinta pode se entender que para cada banda de frequências se a dinâmica das suas características, no tempo e na frequência, for positiva lhe é atribuído o valor 1 e caso seja negativa lhe é atribuído o valor 0. Gera-se assim uma sub-fingerprint (sub-“impressão digital”) para cada janela temporal em que cada sub-fingerprint terá 33-1=32 bits de comprimento.
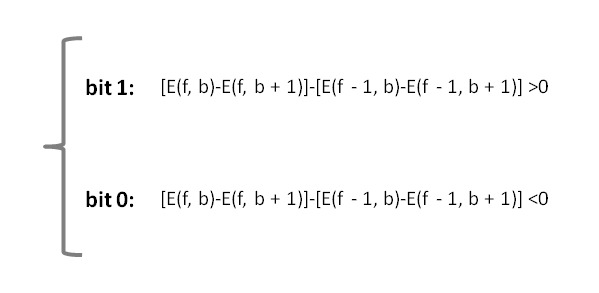
Em que f é o frame temporal a ser analisado, f - 1 o frame que o precedeu, b a sub-banda de frequência, b + 1 a sub-banda de frequência seguinte e E(f,b) a energia do sinal de pico no frame e sub-banda em análise.
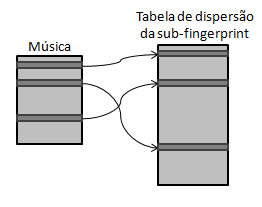
Pode-se então depreender que em 3 segundos de amostra dão origem a uma impressão digital de 256*32/8=1024 Bytes. Considerando que uma música tem em média 3 minutos, seria precisos 60KBytes para ter a impressão digital de toda a música na base de dados. O que obrigaria a ter uma base de dados de tamanho gigantesco para armazenar as impressões digitais de todas as músicas. Para resolver este problema de uma forma simples, as impressões digitais são então guardadas na base de dados em tabelas de dispersão. Desta forma não só se reduz o tempo de pesquisa na base de dados como o tamanho desta. Sendo que cada valor da tabela de dispersão irá apontar para a posição em memória da sub-amostra de música que lhe deu origem.
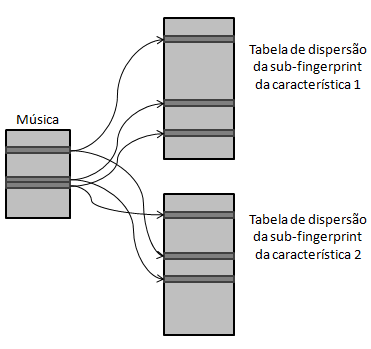
Algoritmos mais elaborados, utilizam como características os coeficientes DCT do sinal em cada frame temporal, os coeficientes MFC (mel frequency cepstral), ou até os decisores presentes no MPEG-7 como o áudio flatness. Derivadas, média e variância das destas características também são muitas vezes utilizadas na caracterização do sinal.
A arquitectura destes algoritmos também acaba por ser mais elaborada. Imagine-se o caso de se querer analisar os N primeiros termos da DCT ao longo do tempo, em vez de uma tabela de dispersão a conter a impressão digital, o algoritmo poderá utilizar N tabelas, uma para cada um dos coeficientes DCT. Desta forma conseguir-se-ia aumentar a robustez do código uma vez que um frame temporal passaria a ser descrito por N sub-fingerprint e não apenas por uma, aumentando assim a fidedignidade do código. A mesma estratégia é utilizada nos códigos que utilizam mais do que uma característica como âncora de apoio na procura da impressão digital mais robusta.
Devido ao facto da grande correlação entre frames temporais seguidos, visto que 31/32=96.875% do frame é igual, certos algoritmos fazem procuras a profundidades maiores, não comparando dois frames adjacentes, mas sim frames espaçados de T ms.
Procura na Base de Dados
Depois de gerada a impressão digital do sinal é chegada a altura de proceder à procura de impressões digitais similares na base de dados.
Algoritmos de pesquisa como o utilizado por Avery Wang no seu trabalho, fazendo uso do Philips Robust Hash (PRH) algorithm proposto por Haitsma et al. Assumem que pelo menos uma das sub-amostras da query de áudio não foi afectada por ruído. Tendo este pressuposto em mente é fácil perceber que a primeira pesquisa se fará tendo em conta os resultados da função de dispersão usada para guardar as impressões digitais de forma a ocuparem o menor tamanho em memória possível. Isto faz com que a primeira pesquisa seja sensivelmente rápida pois não obriga a descodificar música a música para encontrar uma correlação perfeita entre impressão digital da sub-amostra (sub-fingerprint) e sub-fingerprints de todas as músicas.
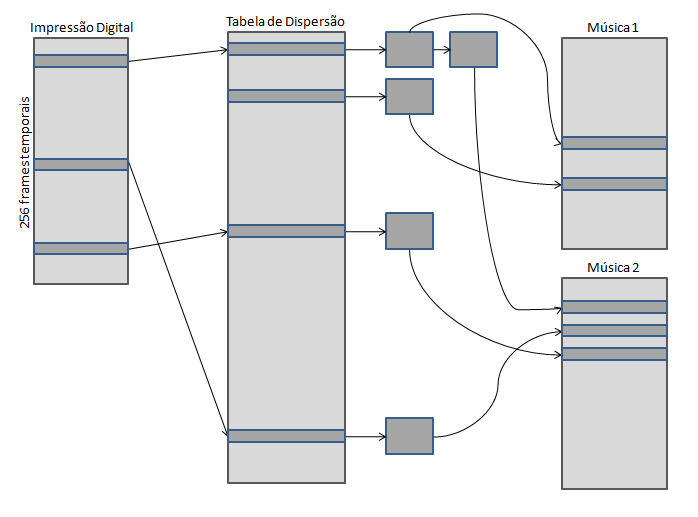
Depois de achados os candidatos, músicas que apresentam pelo menos uma sub-fingerprint exactamente igual a uma sub-fingerprint da amostra a ser testada, os frames temporais restantes da amostra serão testados, música a música, tendo em conta a probabilidade de aquela música corresponder à música da amostra. Isto é, se aquando do primeiro varrimento de pesquisa uma música tiver a si associadas mais frames temporais da amostra que as outras músicas, essa música é então entendida como a maior candidata a ser a música que se procura, dessa forma ela é a primeira a ser testada. E assim sucessivamente, música a música.
Outro factor importante que pode diminuir bastante o tempo de procura prende-se com o facto de embora a temporização da amostra possa ser diferente da das músicas em memória, se esta for igual em termos relativos estamos perante uma boa correlação.
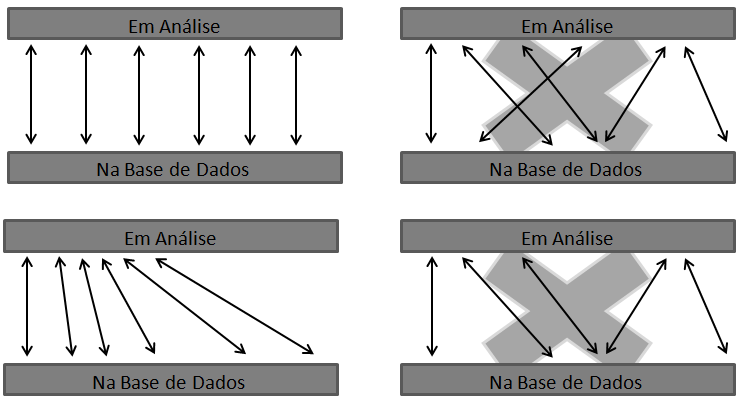
No canto superior esquerdo temos uma correlação perfeita tanto em termos de ordenação como em termos de temporização. No canto inferior esquerdo as sub-fingerprints encontram-se amostradas pela ordem correcta mas temporariamente mais rápidas que a música original, este caso é considerado como uma boa correlação. Do lado direito temos dois exemplos de má correlação de sinal, no canto superior direito observa-se que a música não está de todo temporariamente uniforme nem ordenada. Já no canto inferior direito é possível observar que apesar de as sub-fingerprints aparecerem pela mesma ordem tanto na base de dados como na amostra apresentada a temporização destas apresenta um cariz demasiado aleatório para se poder considerar que estamos perante uma boa correlação de resultados.
Um facto importante a ter em conta é que a incorrecta correspondência entre uma sub-amostra e a sua sub-fingerprint, não leva obrigatoriamente a um mau reconhecimento da música, uma vez que uma query de áudio tem inúmeras sub-amostras associadas. Sendo por isso menos importante relacionar uma sub-amostra com a sua sub-fingerprint do que a impressão digital no seu todo com a música. Isto permite que se possa ter um cálculo menos cuidado quando se está a traçar a impressão digital da query áudio, sempre que essa diminuição de complexidade de cálculo levar a um aumento da performance do algoritmo de pesquisa.
Casos Mais Complexos
Poder-se-á então questionar: E se o ruído que envolve o sinal for tão grande que nenhuma das sub-amostras resistiu intacta?
Existem algoritmos mais pesados que já contemplam esta hipótese, ao usarem funções de dispersão criptográficas como a Message Digest 5 ou a Cyclic Redundancy Checking que devolvem valores completamente diferentes no caso de apenas um bit ser alterado, parece impossível testar de uma forma simples se existem impressões digitais similares nas bases de dados.
A forma intuitiva de contornar esta dificuldade seria alterar um a um os bits da impressão digital da amostra a ser testada e procurando na tabela de dispersão da base de dados cada um destes testes. Como é notório e relembrando que 3 segundos de áudio dão origem a uma impressão digital com 8192 bits, é fácil perceber que o custo computacional de tal abordagem seria astronómico, mesmo que só se considera-se alterar um bit em cada teste teríamos que testar 8192 novas combinações. Se se tentasse ir mais longe e fosse preciso admitir 2 bits errados entre os 32 bits de cada sub-fingerprint o número de testes seria ainda maior.
Voltando ao algoritmo apresentado por Avery Wang e à forma como ele avalia se um bit da impressão digital é 1 ou 0, através da análise da gama dinâmica do sinal. Conseguimos perceber que casos em que a variação da energia do sinal foi muito agravada são tratados da mesma forma de quando esta é muito leve. Considerando que o sinal sofreu ruído é mais provável que o ruído traduza mudanças ténues na dinâmica do sinal do que acentuadas. Podemos por isso considerar que quando a variação dinâmica foi elevada estamos perante um bit de credibilidade elevada e nos casos em que esta é baixa, estamos perante bits de baixa credibilidade.
Sendo assim, os primeiros bits a serem alterados na tentativa de descobrir novos valores de dispersão que nos levem a resultados positivos na procura de correlação na tabela de dispersão da base de dados, devem ser os bits aqui descritos como de baixa credibilidade.
Para outros algoritmos de pesquisa, que não o de Avery Wang, o caminho a seguir será o mesmo. Atribuir um patamar de segurança a cada nível de análise e dizer que os bits que resultam de valores abaixo desse patamar devem ser os primeiros a ter em conta quando se considera que nenhuma das sub-amostras conseguiu resistir ao ruído atribuído pelo percurso do sinal. E os que estiverem acima desse patamar os últimos a ser testados.