

A codificação estéreo convencional consiste apenas em codificar a imagem a transmitir para um olho e de seguida codificar a imagem a transmitir para o outro olho em relação à primeira (utilizando, por exemplo, compensação de movimento) uma vez que as duas são muito parecidas, sendo captadas de ângulos ligeiramente diferentes.
Quanto a vídeo multi-vista, além da sua utilização integrada com lentes lenticulares já referida, este também pode ser utilizado em vídeo de vista livre (FVV) que é um sistema de vídeo que fornece aos utilizadores a habilidade de navegar interactivamente pelo conteúdo filmado e escolher uma de várias vistas numa cena de vídeo.
A codificação de vídeo com múltiplas vistas (MVC) é efectuada com base em codificação inter-vistas, ou seja, codifica-se a informação redundante entre vistas adjacentes.
Esta codificação é adicionada à já realizada codificação temporal que se baseia na codificação de imagens vizinhas no tempo, eliminando redundância, uma vez que duas imagens vizinhas no tempo são normalmente muito parecidas.
Esta codificação é definitivamente necessária para diminuir a quantidade de dados que se tem de transmitir para produzir vídeo com múltiplas vistas, que poderia tornar-se insustentável.
Duas imagens vizinhas no espaço são normalmente menos idênticas que duas imagens vizinhas no tempo. Além disso na codificação espacial pode existir o problema de oclusão de objectos, isto é, objectos visíveis numa vista estarem tapados nas vistas adjacentes.
Ainda assim existem vários algoritmos de codificação MVC que se baseiam em dependências estatísticas espácio-temporais.
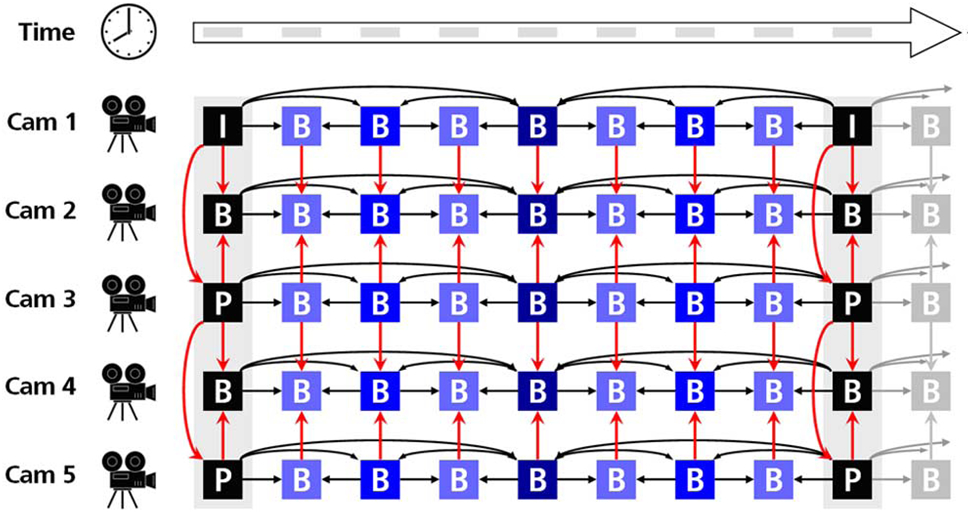
Os resultados deste tipo de codificação dependem de propriedades como a distância entre as câmaras e as cenas adquiridas, o frame rate de transmissão (imagens por segundo) e a complexidade do conteúdo (textura, movimento). Algoritmos MVC baseados na sintaxe do codec H.264/AVC (testados antes de 2008) foram dos testados os que obtiveram os melhores resultados, em experiências desenvolvidas no contexto de normas MPEG. O ganho destes algoritmos (comparativamente à codificação de múltiplos streams de vídeo relacionados espacialmente como sendo independentes) na relação sinal-ruído de pico variou entre menos de 0.5 e mais de 3 dB neste tipo de algoritmos, dependendo do conteúdo codificado.
Este tipo de sistemas contém alguma complexidade computacional e possui requisitos de memória devido a atrasos causados por processamento de dados.
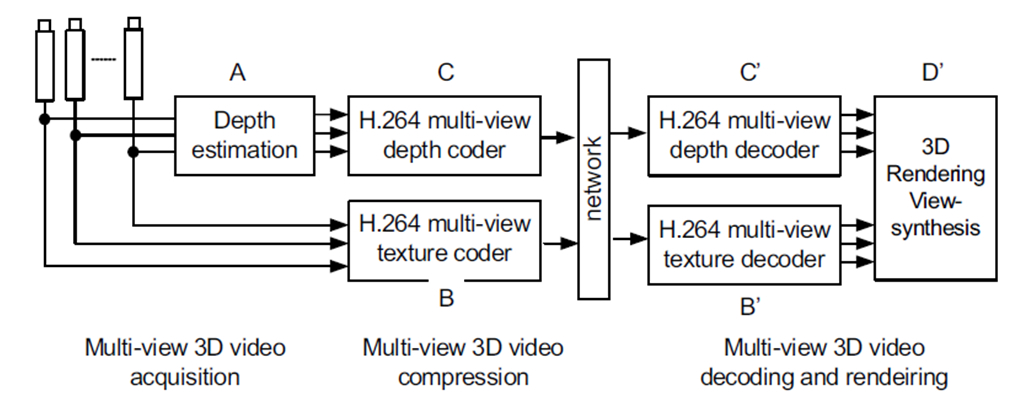
Outro método de evitar o aumento da transmissão de informação com o aumento do numero de vistas caso se queira produzir vídeo multi-vista, é o de colocar o peso da complexidade no receptor.
A codificação 2D + profundidade (2D+Z) consiste em enviar uma imagem 2D a cores e a sua respectiva informação de profundidade codificada em luminância. Se forem utilizados 8 bits para codificar a luminância como é habitual nos sistemas de televisão, podem existir 256 níveis de profundidade diferentes numa dada imagem, do mais próximo (255 que corresponde a branco) ao mais longínquo (0 codificado como preto), cobrindo-se pela mesma lógica todos os valores intermédios em tons de cinzento.
O receptor caso possua um sistema de processamento de imagem, pode criar múltiplas vistas da imagem recebida através da sua respectiva informação de profundidade sendo que para qualquer número de vistas produzidas, o aumento no débito binário emitido é sempre o mesmo e apenas de mais 10-20% de forma a emitir a informação da profundidade do conteúdo a boa qualidade.
