As normas para codecs de vídeo, desenvolvidas por esta organização, satisfazem os conteúdos de multimédia digital na indústria do consumo electrónico. Este tipo de indústria também aderiu ao vídeo digital, pelas diversas vantagens e serviços adicionais que isso proporciona. É a normalização que permite a interoperabilidade e a economia de escala [10, 11].
MPEG-1
O vídeo armazenado nas fitas VHS é analógico. O MPEG-1 surge como a norma que permite comprimir vídeo digital, garantindo um débito, qualidade e resolução ao mesmo nível ou superior, em relação ao já existente no VHS [10].
Objectivos
O objectivo do MPEG-1 foi conseguir garantir a compressão de vídeo digital, em equipamentos de armazenamento convencionais, por exemplo CD, assegurando uma boa qualidade, para débitos até 1.5 Mbit/s [10]. Pretende ainda fornecer condições como o acesso aleatório, a facilidade de edição e a realização de fast forward ou fast reverse [10].
Arquitectura
A arquitectura de codificação de vídeo na norma MPEG-1 é bastante similar à arquitectura da recomendação H.261. Utiliza um modelo híbrido, conjugando a predição temporal com a transformada DCT. Esta norma apenas define o formato do fluxo de dados comprimidos e a arquitectura do descodificador.
O codificador de fonte estima os vectores de movimento, calcula o erro de predição, procede à transformada DCT e à quantificação dos blocos resultantes. Os símbolos são depois codificados entropicamente, através de códigos VLC [10].
Formato das imagens originais
As imagens aceites para a codificação em MPEG-1, são analisadas de forma progressiva, sendo consideradas as suas três componentes Y, Cr e Cb. O formato de subamostragem das crominâncias mantém-se, tal como no H.261, em 4:2:0. Apesar de esta norma aceitar imagens de resoluções entre 1 e 4095 em cada uma das direcções, tipicamente as imagens são de resolução SIF (Source Input Format), com 352x240 pixéis.
Formato do fluxo de dados
O fluxo de dados gerado por um codificador MPEG-1 é organizado em sequências de imagens codificadas. Cada uma define parâmetros de codificação e é constituída por um conjunto de GOP (Group Of Pictures). A estrutura típica de um GOP está representada na Figura 1. N é a distância, em imagens, que separa duas imagens I, enquanto M é a distância que separa duas âncoras I/P e P. Cada imagem é dividida em slices, cada um constituído por um grupo de macroblocos, de estrutura semelhante aos do H.261.
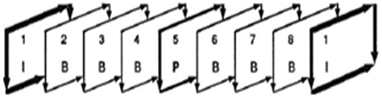
Figura 1 - Estrutura de um GOP [10].
Ferramentas
Imagens I, P, B e D
As imagens I (Intra), codificadas sem qualquer dependência sobre as restantes, servem de ponto de referência e garantem o acesso aleatório. As imagens D (Intra), também exploram apenas a redundância espacial, no entanto apenas utilizam os coeficientes DC, servindo o propósito do fast foward. As tramas P e B (Inter) exploram redundância temporal, aumentando os factores de compressão, no entanto as P apenas são preditas tendo em conta a última P ou I do passado, enquanto as B são preditas usando a última P ou I do passado e a P ou I seguinte no futuro [4].
Estimação e compensação de movimento
O processo de estimação do movimento é bastante semelhante ao utilizado no H.261, contudo a precisão na pesquisa dos vectores de movimento é de ½ pixel e as janelas de pesquisa podem ter tamanhos variáveis. As predições nas tramas B são feitas no passado e no futuro, como é possível visualizar na Figura 2, e os vectores de movimento são codificados em relação à diferença entre eles e os restantes da slice [4].

Figura 2 - Predição Bidireccional [10].
DCT, Quantificação e Codificação entrópica
A DCT transforma os blocos de 8x8 pixéis no domínio das frequências, explorando a redundância espacial. A quantificação dos coeficientes da DCT é feita, nas tramas Intra com uma matriz de quantificação variável, enquanto as tramas Inter são quantificadas recorrendo a uma matriz de quantificação constante. Os coeficientes DC da DCT são codificados diferenciadamente em relação aos restantes do mesmo macrobloco. Após a quantificação, segue-se a codificação entrópica, com pares (Run, Level) e recorrendo a códigos de comprimento variáveis (VLC) [4].
Codificação forçada de tramas I (Intra)
A opção de refrescamento dos macroblocos, consiste na codificação de macroblocos de modo Intra, de modo a conter possíveis propagações de erro ao longo das predições [4].
MPEG-4 Visual
Com a evolução da tecnologia, tornou-se mais fácil produzir conteúdos audiovisuais. Assim, cada pessoa passou a representar um possível produtor de conteúdos, que facilmente poderiam ser distribuídos e consumidos, por exemplo, via Internet. O consumo de conteúdos audiovisuais em vários tipos de redes e terminais, com requisitos de interoperabilidade diferentes, deu origem ao desenvolvimento de uma nova norma de codificação audiovisual, o MPEG-4 Visual [4].
Objectivos
O MPEG-4 Visual tem como principal objectivo oferecer novas maneiras de comunicar, aceder e manipular informação digital audiovisual, baseadas nomeadamente no próprio conteúdo. Até então, o conteúdo não tinha nenhum papel na representação desse mesmo conteúdo, ou seja, o conteúdo era representado como uma matriz de pixéis [4].
Arquitectura
Na sequência das funcionalidades identificadas, para as quais o próprio conteúdo assume um papel fundamental, o MPEG-4 adoptou um novo modelo de dados para a representação audiovisual, centrado na noção de “objecto”. Assim, o “objecto” é o elemento básico do mundo audiovisual que se pretende representar, como é possível visualizar na Figura 3.
Figura 3 - Arquitectura da representação visual MPEG-4 [4].
A cena audiovisual é modelada como uma composição de objectos codificados de forma independente, ainda que existam entre eles relações espaciais e temporais. O conjunto desses objectos recriam o mundo representado, mas com os quais é possível interagir de modo individual. Este tipo de representação está mais próximo do mundo real e da relação do Homem com este, o que traz algumas vantagens, por exemplo, os objectos em MPEG-4 podem ser de vários tipos: texto, imagem ou vídeo. Contudo, cada um destes objectos mantém a sua individualidade, podendo ser codificados com ferramentas adequadas ao tipo de dados em questão, por exemplo, o texto é representado com ferramentas de codificação de texto e não de vídeo. Além disso, os objectos podem ser reutilizados em cenas diferentes, trazendo vantagens em termos de rapidez e economia de produção de novos conteúdos [4].
A norma MPEG-4 define vários descodificadores e correspondentes sintaxe e semântica dos fluxos binários, cada um deles específico para um tipo de dados, de modo a conservar a individualidade de cada tipo de objecto. Além disso, para tipos de dados mais importantes, como o vídeo, podem ser definidas várias soluções de codificação, com diferente eficiência de compressão e complexidade [4].
Ferramentas
Nesta secção apresentam-se as ferramentas de compensação de movimento, especificadas na norma MPEG-4 Visual para codificação de objectos de vídeo, com forma rectangular e arbitrária. Os objectos de vídeo, rectangulares ou com forma arbitrária, são codificados em blocos quadrados porque este é o modo mais eficiente de codificar a textura de uma sequência de vídeo [4].
Em MPEG-4, cada cena é composta por um ou mais Visual Objects (VO). No caso das sequências de vídeo, o VO é do tipo vídeo e é definido como uma sequência de Video Objects Planes (VOP). Fazendo uma analogia ao MPEG-2, um VOP corresponde a uma única imagem, enquanto o VO corresponde a toda a sequência de vídeo. A codificação de cada VOP é feita com base na sua divisão em macroblocos (MB) com 16 x 16 amostras de luminância e as correspondentes amostras de crominância, dependendo do formato de subamostragem [4].
Existem dois modos principais de codificação, o modo Intra e o modo Inter. No modo Intra as amostras de luminância e crominância, para cada MB (Macrobloco), são codificados independentemente de VOP antecedentes ou futuros. No modo Inter é codificado o erro de predição entre as amostras de luminância e crominâncias do MB, em relação a valores de predição obtidos de VOP passados e/ou futuros. A vantagem do modo Inter, deve-se ao facto de apenas serem codificadas as diferenças em relação ao VOP de referência e não o VOP completo. Este princípio é conhecido como codificação preditiva, o codificador procura primeiro uma predição e só depois o erro de predição, explorando a redundância temporal [4].
A compensação de movimento a ¼ de pixel, em vez de ½ pixel tal como em normas anteriores, permite obter melhores imagens de predição, diminuindo assim o erro de predição. Outra ferramenta, utilizada na norma MPEG-4 Visual, é a compensação de movimento global, onde um único conjunto de parâmetros de movimento é usado em todo o VOP. Estes parâmetros podem ser usados em alternativa aos vectores de movimento locais de cada MB [4].
A predição bidireccional em modo directo é a ferramenta que permite melhorar a predição com compensação de movimento bidireccional. Este processo corresponde a uma generalização do modo PB especificado na recomendação H.263 [4].