O MPEG (Moving Picture Experts Group) é um grupo de especialistas em vídeo, formado pela ISO / IEC, que tem como objectivo a definição de normas para a compressão e transmissão de áudio e vídeo. O VCEG (Video Coding Experts Group) é um grupo formado pela ITU-T, que tem como responsabilidade a normalização das recomendações de codificação de vídeo H.26x. Em seguida apresenta-se duas normas de codificação de vídeo, cujas especificações são o resultado da colaboração entre os dois grupos.
H.262
A procura de soluções de codificação de vídeo para aplicações como o armazenamento digital, comunicação de dados audiovisuais e difusão de televisão, fez com que o grupo de trabalho MPEG em colaboração com o grupo VCEG define-se uma nova norma de vídeo, o MPEG-2 Vídeo (MPEG-2 Parte 2), também conhecido como H.262. Globalmente, a norma MPEG-2 é constituída por dez partes, no entanto, no âmbito deste artigo apenas será abordada a parte de Vídeo [4].
Objectivos
Esta norma foi desenvolvida com o objectivo de fornecer um sinal de vídeo digital, com uma qualidade entre NTSC/PAL e ITU-R 601 [2], para débitos binários até 10 Mbit/s. Os débitos acima dos 10 Mbit/s estavam reservados para aplicações HDTV, para as quais seria criada uma nova norma, o MPEG-3. Contudo, os requisitos do MPEG-3 foram incluídos no MPEG-2, dado que este provou ser capaz de codificar imagens HDTV de modo eficiente, razão pela qual o MPEG-3 não foi definido. A lista de aplicações é um pouco extensa, em seguida apresenta-se um excerto: televisão de definição standard (SDTV); televisão de alta definição (HDTV); gravação digital de vídeo (CD e DVD); vídeo-on-demand; streaming sobre canais ATM [4].
Arquitectura
A arquitectura de um codec de vídeo MPEG-2 é semelhante à arquitectura adoptada pela norma MPEG-1Vídeo. Ambas utilizam um codificador híbrido, que utiliza a estimação e compensação de movimento para explorar a redundância temporal e a DCT para explorar a redundância espacial, codificando blocos da imagem original no modo Intra e as imagens de erro resultantes da predição no modo Inter. A utilização de imagens do tipo B obriga a um reordenamento das imagens antes da codificação, ou seja, as imagens I e P usadas como referência, devem ser codificadas antes da respectiva imagem do tipo B. Consequentemente, é necessário fazer uma reordenação das tramas no descodificador, antes da sua visualização, o que pode introduzir algum delay [4].
O processo de codificação é muito semelhante ao processo de descodificação, aplicando-se as operações inversas. A Figura 1 representa a estrutura de blocos do processo de descodificação, onde o fluxo de dados é descodificado a partir das palavras de comprimento variável recebidas. Em seguida, os coeficientes DCT são reconstruídos pelo quantificador inverso (Q-1). Por fim, aplica-se a DCT inversa (IDCT) para se obter as amostras ou resíduos, consoante se trata da codificação Intra ou Inter. A compensação de movimento (MC) é feita com ajuda dos vectores de movimento, sempre que existe imagens do tipo P ou B. O erro residual passa pelo processo de quantificação inversa e IDCT, sendo o resultado adicionado à memória que contém a imagem de predição, construída usando vectores de movimento [4, 10].
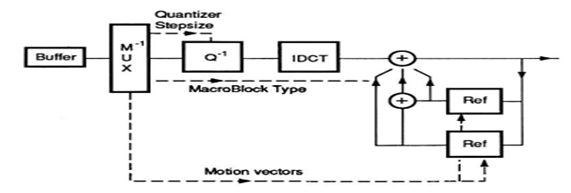
Figura 1 - Diagrama de blocos de um descodificador MPEG-2 [10].
Ferramentas
MPEG-2 Vídeo definiu vários perfis, subconjuntos da sintaxe do fluxo de dados, e níveis, conjuntos de restrições impostas aos parâmetros do fluxo de dados. Além disso, inclui novos modos de predição, de modo a suportar a codificação de vídeo entrelaçado e extensões para codificar vídeo escalável. A codificação de vídeo escalável oferece uma maior interoperabilidade entre terminais com diferentes capacidades, por exemplo, em termos de resolução espacial ou de débito binário. Os terminais podem utilizar subconjuntos do fluxo binário total, para obter uma representação do vídeo com menor resolução ou qualidade, adequando-se assim às suas capacidades [4].
A codificação de vídeo entrelaçado consiste em codificar separadamente as linhas ímpares e pares de uma imagem, formando-se assim dois campos, o campo par e ímpar. Se os dois campos de uma trama tiverem sido adquiridos em instantes diferentes, a trama é designada por entrelaçada, caso contrária, é designada por progressiva. Como as linhas que pertencem ao mesmo campo estão temporalmente mais próximas entre si, cada campo é codificado separadamente. A predição entre macroblocos de imagens de vídeo entrelaçado pode ser efectuada entre tramas, como no vídeo progressivo, ou entre campos. A predição de trama é mais eficiente quando existe movimento muito lento de objectos, por outro lado, a predição de campo é mais eficiente quanto existe movimento mais rápido. A escolha é feita pelo codificador segundo critérios não normativos [4].
H.264 / AVC
Com o aparecimento das novas redes de acesso, tais como, o cabo, o DSL (Digital Subscriber Line) e o UTMS (Universal Mobile Telecommunications System), surgiu a necessidade de aumentar os factores de compressão para a informação de vídeo. Assim, foi definida uma nova norma, o H.264/AVC (MPEG-4 Parte 10), intitulada AVC (Advanced Video Coding) [4].
Objectivos
A norma H.264 / AVC tem como principal objectivo a codificação de vídeo de forma eficiente, aproveitando os conhecimentos e o que de melhor têm as normas que lhe antecederam. Além disso, pretendia alcançar, para uma vasta gama de débitos, uma capacidade de compressão de cerca do dobro das melhores soluções normativas previamente existentes. Contudo, pretendia-se alcançar a mesma qualidade subjectiva e além disso, pedia-se especial consideração ao desempenho em canais com erros, nomeadamente em canais móveis e Internet. A lista de aplicações é extensa, em seguida apresenta-se um excerto: difusão via cabo, satélite e terrestre; armazenamento (DVD, Blu-Ray); video on demand; streaming via RDIS, cabo, DSL, LAN, redes sem fios e móveis [4].
Arquitectura
A norma H.264/AVC é baseada numa arquitectura híbrida de codificação de vídeo, onde se combina a predição no tempo com a transformada no espaço, ver Figura 2. Semelhante às arquitecturas já descritas neste artigo, cada imagem à entrada do codificador é dividida em macroblocos. Sendo que, cada macrobloco é constituído por três componentes: a luminância, Y, e duas crominâncias, Cb e Cr. Como também já foi referenciado neste artigo, o sistema visual humano é menos sensível à crominância do que à luminância. Assim, os sinais de crominância são subamostrados com um factor 2, na horizontal e na vertical, em relação à luminância (formato 4:2:0) [4, 12].
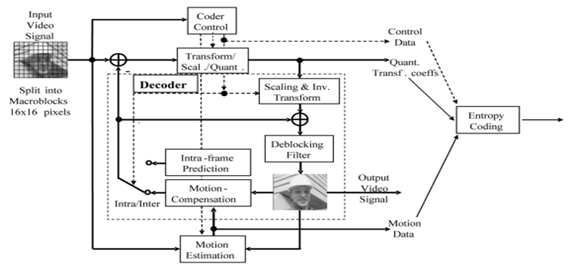
Figura 2 - Arquitectura de codificação H.264/AVC [12].
Cada um dos macroblocos pode ser codificado no modo Intra ou no modo Inter. No modo Inter, cada macrobloco é predito usando informação de outras imagens, tipicamente usando compensação de movimento. No modo Intra, ao contrário das outras normas que usam uma predição nula, o H.264/AVC utiliza uma predição espacial para os macroblocos dessa mesma imagem. A codificação no modo Intra é importante, uma vez que permite ao sistema ser mais robusto a erros de canal e também garante acesso aleatório [4, 12].
O erro de predição, correspondente à diferença entre os blocos originais e de predição, é transformado, quantificado e entropicamente codificado. O descodificador reconstrói a imagem, aplicando a transformada inversa aos coeficientes quantificados e adicionando o resultado ao bloco predição. Este mesmo processo é realizado no codificador, de modo a que este disponha, para efeitos de predição, da mesma imagem descodificada de que dispõe o descodificador. Este modo de funcionamento é correcto para canais ideais, uma vez que é nestas condições que se faz a especificação do funcionamento do descodificador [4]. Em canais não ideias (mundo real) tem que existir compensação de erro, o modo como esta se faz não é normativo.
Ferramentas
Nesta secção apresenta-se algumas das ferramentas mais importantes, visando benefícios em termos de eficiência de compressão, por melhorarem a qualidade das predições. A norma H.264/AVC oferece maior flexibilidade na selecção da forma e tamanho dos blocos para efectuar compensação de movimento, que pode ir até 4 x 4 amostras para a luminância. Esta norma remove também a dependência estrita entre a ordem das imagens usadas como referência na compensação de movimento, e a ordem das imagens na visualização. Assim, na norma H.264/AVC o codificador pode escolher com maior liberdade a ordem das imagens usadas como referência. O levantamento deste tipo de restrições permite, por exemplo, remover o atraso adicional associado à codificação bipreditiva ou de tipo B, por exemplo, fazendo codificação bipreditiva a partir de duas imagens passadas [4].
Tal como as normas de codificação de vídeo anteriores, a norma H.264/AVC utiliza a codificação de transformada para representar o resíduo da predição. No entanto, esta norma não utiliza a DCT, mas sim uma transformada directa, ainda que com propriedades semelhantes. Uma vez que a transformada inversa é definida através de operações inteiras, exactas, evita-se agora o problema de falta de sincronismo, antes associado à DCT inversa porque esta não é definida de maneira precisa em termos de implementação [4].
De modo a reduzir o efeito de bloco, a norma H.264/AVC especifica um filtro adaptativo, que opera nas fronteiras do bloco, de modo a suaviza-las, melhorando a qualidade subjectiva da imagem. Este filtro está presente no codificador e descodificador, uma vez que filtra os blocos depois de estes serem descodificados e está incluído no loop de predição. Os blocos filtrados são utilizados na compensação de movimento, dando origem a um resíduo mais suave depois da predição e reduzindo o débito binário [4].