|
Desde
a expansão da Internet nos anos 90, o MPEG-1/2 Layer-3
é considerado um caso de sucesso comparativamente com outras
tecnologias de
compressão áudio. Tal facto deve-se essencialmente ao aparecimento de
computadores
rápidos a processar, descodificar e codificar ficheiros áudio, placas
de som
para o mercado doméstico, difusão do CD-ROM e CD-Audio por parte das
editoras e
distribuidores de música e a partilha ilegal de ficheiros áudio. Ser um
padrão
aberto teve um profundo impacto na interoperabilidade dos equipamentos,
dando
aos fabricantes grande margem de manobra no desenvolvimento de
melhoramentos ao
nível da codificação e descodificação de dados áudio MPEG sem alterar o
código base.
A
primeira fase do trabalho do grupo MPEG (Moving Pictures Experts
Group) recebeu o nome MPEG-1 sendo iniciado em 1988 e término em no
final de 1992.
A secção de codificação áudio do MPEG-1 descreve um sistema de
codificação
genérico, desenhado para corresponder às exigências de muitas
aplicações e
consiste em três modos denominados Layers,
aumentando em complexidade e desempenho da Layer-1 para a Layer-3. Esta
última
apresenta o modo com maior complexidade e optimizado para dar alta
qualidade a
débitos baixos, aproximadamente 128 kbit/s para um sinal stereo. A Layer-2 aplica
o modelo Psico-acústico de forma mais eficiente, é capaz de suprimir
mais
redundância num sinal e requer uma codificação/descodificação mais
complexa do que
a Layer-1. Por fim a Layer-1 possui baixa complexidade e é direccionada
para
aplicações onde o codificador desempenha um papel crítico.
Após a sua
elaboração em 1991, o MPEG-1 Layer-3 foi fonte de
diversas investigações no que toca a técnicas de codificação perceptiva
e de
eficiência de compressão. A tarefa de um sistema de codificação de
percepção áudio
é, fundamentalmente, comprimir dados de áudio digital de forma
eficiente e reconstruir
os dados áudio nos dados áudio originais, dentro do possível. A baixa
complexidade é outro dos requisitos ao desenvolver técnicas de
compressão áudio
assim como a flexibilidade para utilização numa panóplia de aplicações.
Esta
técnica é designada Codificação Perceptiva e usa o conhecimento do
sistema acústico
humano (modelo Psico-acústico) para obter eficiência com compressão de
informação irrelevante (técnica de compressão com perdas), em que os
dados
descodificados não são réplicas exactas ao bit dos dados originais.
Na figura em baixo é apresentado um diagrama de blocos
simples de um sistema de
codificação perceptiva. O bloco Filterbank é usado para decompor o
sinal de
entrada em componentes espectrais sub-amostradas no dominó
tempo/frequência,
formando um sistema de análise/síntese juntamente com o Filterbank no
descodificador. O Perceptual Model usa o sinal de entrada no domínio do
tempo
e/ou o sinal de saída do Filterbank de análise para gerar uma
estimativa do
limiar (threshold) actual de camuflagem (e que depende do tempo e da
frequência), usando as propriedades do Modelo Psico-acústico. A
quantização e
codificação das componentes espectrais permitem manter o ruído,
introduzido
pela quantificação, abaixo do limiar. Finalmente, no bloco Encoding of
Bitstream os coeficientes espectrais quantizados e codificados são
agregados juntamente com
alguma informação complementar (side information).
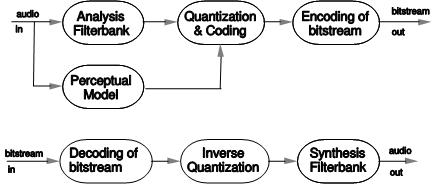
Diagrama de Blocos de um sistema de
codificação perceptiva
O
MPEG-2 é a segunda fase do MPEG e introduziu muitos novos
conceitos, especialmente na codificação de vídeo uma vez que a
televisão
digital era o principal âmbito deste padrão. Em 1994, o padrão de áudio
MPEG-2
original consistia apenas em duas extensões do MPEG-1, suporte para
compatibilidade
directa e inversa na codificação de sinais multicanal, e a adição das
frequências de amostragem 16 kHz, 22.05 kHz e 24 kHz às frequências de
amostragem típicas do MPEG-1, permitindo uma codificação eficiente a
débitos
baixos. Na secção AAC
deste estudo será apresentado em mais detalhe o MPEG-2
Advanced Audio Coding (AAC), um sistema de codificação genérico para
sinais stereo
e multicanal.
|

