Descrição
O algoritmo AAC explora fundamentalmente duas premissas que permitem que a quantidade de dados necessária para codificar o sinal de áudio seja inferior:
Os componentes do sinal que são irrelevantes perceptualmente são descartados.
As redundâncias existentes no sinal codificado são eliminadas.
O formato AAC suporta até 48 canais de áudio, utilizando uma frequência de amostragem entre os 8kHz e os 96kHz. Além disso, o codificador suporta três modos diferentes de operação:
Main profile, no qual o sinal é codificado com a máxima qualidade possível.
Low complexity, que consegue sensivelmente a mesma qualidade com uma codificação computacionalmente mais eficiente.
Scalable Sample Rate (SSR), que fornece soluções para aplicações de baixa complexidade. Este modo permite fazer descodificação PCM para uma gama de diferentes taxas de codificação.
Codificação
O diagrama do processo de codificação é apresentado na figura 5:
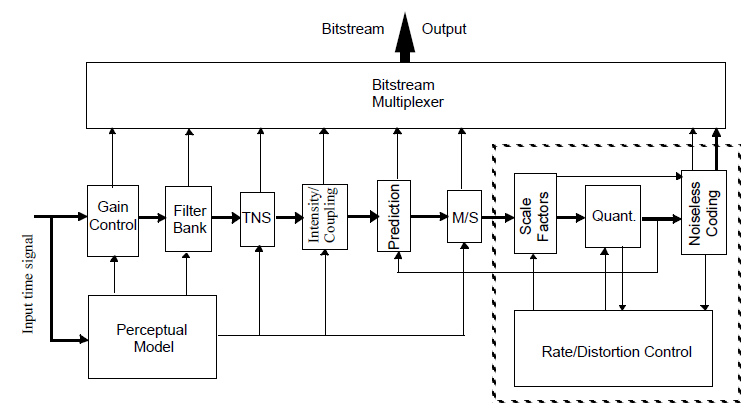
Figura 5 - Esquema de codificação AAC
A finalidade de cada um dos blocos constituintes deste algoritmo explica-se seguidamente:
Gain Control – Consiste num pré-processamento que utiliza uma Pseudo Quadrature Mirror Filter (PQMF) de 4 bandas uniformes com detectores e modificadores de ganho.
Banco de Filtros – Tem como finalidade decompor o sinal nas diferentes componentes espectrais seja no tempo ou na frequência. Se se estiver no modo Main Profile ou Low Complexity, o banco de filtros utiliza a Modified Discrete Cosine Transform (MDCT), em que o bloco de transformação oscila entre 1024 e 128 pontos de frequência. É vantajoso o bloco ser mais pequeno quando há uma alteração repentina no sinal, e maior no caso em que o sinal está estável, o que permite uma maior eficiência na codificação. No modo SSR é utilizado um banco de filtros híbrido, que consiste num Polyphasic Quadrature Filter (PQF) em série com um MDCT com blocos de transformação entre 256 e 32 pontos de frequência.
Temporal Noise Shaping (TNS) – Utiliza a predição no domínio da frequência para modelar o ruído no domínio do tempo de forma a melhorar a resolução temporal do sinal. Quer-se com isto dizer que o erro de quantização pode ser distribuído pelas frequências que perceptivamente não são ouvidas adaptando-se ao perfil temporal do sinal. Os blocos têm de ser mais pequenos para que a resolução seja maior. Todos os perfis utilizam esta ferramenta, mas há algumas limitações nos perfis Low Complexity e SSR.
Intensity/Coupling – Faz uso da Intensity Stereo Technique que tira partido do facto de o sistema auditivo humano ser menos sensível na percepção da direcção quando o som é emitido em certas frequências. Desta forma a compressão aumenta sem afectar a qualidade do áudio. O sinal stereo é transmitido num canal mono, mas contendo contiguamente informação lateral que consiste numa série de coeficientes espectrais que permitem que no final seja possível a codificação como sinal stereo. Esta técnica está sujeita à aparição de artefactos de compressão audíveis, mas na prática, para taxas de codificação baixas, o ganho de qualidade do áudio é alto tendo em conta a percepção.
Prediction – Remove as redundâncias existentes entre os blocos de áudio. Para isso é utilizado o algoritmo Backward-Adaptive Prediction. Os coeficientes de predição não são explicitamente codificados sendo apurados quando a descodificação do sinal é feita. Tem a vantagem de não ser necessário armazenar amostras do futuro, diminuindo o atraso de processamento. O melhor partido deste método é tirado quando o sinal é estacionário, ou seja, quando a codificação é feita em blocos maiores.
Middle/Side Coding (M/S) – Neste bloco, os canais direito e esquerdo são transformados noutros dois sinais – central e lateral – em que o canal central é o resultado da soma do canal direito e do esquerdo ao passo que o canal lateral é a subtracção do sinal dos dois canais. Contrariamente ao que acontece no algoritmo Intensity Stereo Technique, a codificação M/S não introduz artefactos, mantendo a qualidade do sinal original.
Faz-se um pequeno parêntesis para realçar que os blocos anteriores são parametrizados de acordo com o modelo perceptivo para o sistema auditivo. Quer-se com isto dizer que usando o sinal de entrada e/ou o output dos blocos anteriores, é apurada uma estimativa do sinal calculada a partir das regras dos modelos psicoacústicos.
Scale Factor – Para melhorar a qualidade subjectiva do sinal são necessários factores de escala para modelar o ruído. São utilizados para amplificar o sinal em certas bandas espectrais, aumentando a relação sinal ruído (SNR) nas mesmas.
Quantizer – Os coeficiente espectrais são quantificados utilizando um passo não uniforme de 1.5dB. Este passo é fixo dentro de uma banda, mas pode variar de banda para banda. A quantificação é feita usando uma função de quantificação e uma modelação de ruído calculada com recurso ao factor de escala referido no ponto anterior.
Noiseless Coding – Neste bloco é efectuada a codificação de Huffman dos coeficientes espectrais quantificados no bloco anterior. Este método usa múltiplas tabelas com múltiplas dimensões para codificar os valores espectrais. Uma ou mais bandas podem ser agrupadas em secções e ser codificadas usando a mesma tabela de Huffman. Este bloco determina qual é a dimensão mais adequada para as secções e para as tabelas.
53088 – João Costa, jmcst<at>yahoo.com;
55276 – Diogo Lucas, diogodiaslucas<at>gmail.com;
70666 - Stephane Fernandes, saf_jsf<at>hotmail.com;