Camada SILK
A camada SILK do Opus trata-se de uma ferramenta especialmente otimizada para a codificação de sinais de voz que tenta explorar ao máximo a sua redundância, pois apresentam um certo grau de previsibilidade, bem como a sua irrelevância, dado que o ouvido humano possui uma sensibilidade limitada. Com este intuito, o algoritmo descreve estes sinais através de uma representação paramétrica, simplificando-os sem que tal seja percetível ao ouvido humano.
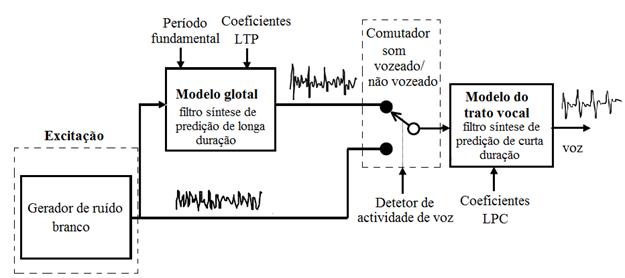
O modelo adotado pela camada SILK tenta imitar a forma como a voz é produzida pelo aparelho fonador humano, isto é, tenta modelar o processo da emissão de ar pelos pulmões e a posterior passagem do mesmo pela glote e pelo trato vocal. Deste modo, o ar emitido pelos pulmões pode ser representado, em linhas gerais, por um gerador de ruído branco (excitação); já as vibrações das cordas vocais e as ressonâncias do trato vocal apresentam-se como filtros que transformam o sinal aleatório num sinal correlacionado. É, também, de referir que é possível dividir a voz em segmen-tos de pequena duração (tramas), aproximadamente de 20ms. As tramas, por sua vez, podem ser classificadas consoante dois tipos de som:
Sons vozeados (ou sonoros) são produzidos pela vibração regular das cordas vocais e, por esta razão, apresentam uma forma de onda quase periódica com um determinado período fundamental. Naturalmente, esta periodicidade tende a alterar-se ao longo da duração de segmentos de fala uma vez que a tensão aplicada às cordas vocais varia.
Sons não vozeados (ou surdos) não fazem uso das cordas vocais e resultam num sinal pouco correlacionado, tendo a correlação resultante sido introduzida apenas pelas ressonâncias do trato vocal.
Durante o processo da fala, quer para sons vozeados como para surdos, verifica-se que a forma das cavidades que constituem o trato vocal tomam diferentes formas, porém a sua variação no tempo é suficientemente lenta de tal modo que num período de uma trama se pode considerar que as suas características se mantêm aproximadamente constantes. Assim, para modelar o trato vocal, o SILK faz uso de um filtro cujos coeficientes variam de trama para trama. Acresce, ainda, o facto de considerar que uma trama pode ser representada a partir da combinação linear de tramas imediatamente anteriores, pelo que o modelo é comumente conhecido como codificação por predição linear LPC. Note-se, finalmente, que os coeficientes do filtro mais não são do que os pesos usados para esta combinação linear.
À semelhança do caso anterior, também é possível definir segmentos temporais nos quais a glote pode ser mo-delada por parâmetros fixos; a sua duração é, porém, de menor duração (5ms) pelo que se denominam de subtramas. Assim, para cada subtrama, é possível extrair um período fundamental que está associado à vibração das cordas vocais e um conjunto de coeficientes. Estes dois parâmetros são de extrema importância dado que, em vez de se explorar a correlação entre amostras consecutivas, a correlação é, agora, explorada entre amostras espaçadas de múltiplos do período fundamental. Este facto leva a que se faça distinção do caso anterior, pelo que estes coeficientes são denominados de coeficientes de predição de longa duração LTP.

