.:
Codificação de MP3 (MPEG-1 Layer 3)
Uma das propriedades mais importantes do padrão MPEG é o princípio de minimizar a quantidade de elementos normativos nele. Na parte MPEG1 audio, tal como no vídeo, somente a representação dos dados (formato do áudio comprimido) e o descodificador são normativos. A norma não especifica o codificador, o que possibilita a evolução na qualidade dos codificadores ao longo do tempo, mantendo sempre a compatibilidade com os descodificadores mais antigos. .: Principais características
.: Modos de operação
• Mono
• Dual Stereo - Canais codificados independentemente (por exmplo, 2 línguas)
• Stereo - Codificação independente mas partilha de campos comuns na trama codificada
• Joint Stereo - acima de 2 kHz, envia-se o sinal L+R e factores de escala para os 2 canais (L e R) uma vez que o ouvido é pouco sensível. Este modo permite débitos mais baixos mas há o perigo de mudanças no som.
• Mono/Stereo (MS) - Os 2 canais são codificados como L+R (middle) e L-R (side) o que permite controlar melhor a localização espacial do ruído de quantificação . Quando os canais esquerdo e direito são muito parecidos (pouca separação estéreo), o canal "side" contém muito pouca informação, economizando bits.
.: Frequências de amostragem
A norma MPEG1 Layer 3 prevê apenas a utilização das frequências 32 Khz, 44.1 Khz (qualidade de CD) e 48 Khz.
.: Débito binário
O áudio MPEG não trabalha só a um débito fixo. A selecção do débito, entre 8kbit/s e 320kbit/s, é deixada ao critério do codificador. A mudança do débito pode ser feita de trama a trama. Isto permite codificação com débito variável ou débito fixo.
.: Descrição do Algoritmo
Uma visão geral do algoritmo codificador de MP3 (MPEG-1 layer III) é descrita no diagrama de blocos da seguinte figura:
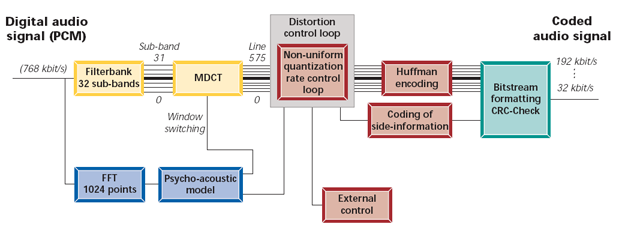
Figura 7 - Codificador MPEG-1 Layer 3
Os dados de áudio de entrada passam através de um banco de filtros que os divide em múltiplas sub-bandas. A filtragem é feita em paralelo com a análise psico-acústica que determina a relação sinal/máscara (SMR) de cada sub-banda. O bloco de controlo de distorção usa as SMR para decidir como dividir o número total de bits de codificação disponíveis. Finalmente, as amostras quantificadas e codificadas são formatadas num bitstream , de acordo com a norma.
.: Banco de Filtros
Ao banco de filtros, chegam blocos de dados com 1152 amostras (2 grupos de 576). Ao passar pelo banco de filtros, as amostras são divididas em 32 sub-bandas, igualmente separadas na frequência. A cada uma destas sub-bandas, é aplicada a Transformada Discreta Coseno Modificada (MDCT) para compensar a baixa precisão do banco de filtros, aumentando-lhe a granularidade. A MDCT é aplicada a cada sub-banda com 50% de sobreposição nas sub-bandas adjacentes, de modo a diminuir o efeito de bloco. Pode ser também usada comutação dinâmica de janela, de modo a diminuir um tipo de efeito indesejável introduzido pela MDCT ao qual se dá o nome de pré-eco .
.: Modelo Psicoacústico
O modelo psicoacústico é um modelo matemático que retrata, de forma simplificada, as principais propriedades e tolerâncias do sistema auditivo humano, nomeadamente a percepção de intensidade sonora, a selectividade espectral e, muito em particular, o efeito do mascaramento. Serve para estimar, adaptativamente, a quantidade e perfil do ruído de codificação que pode ser injectado no sinal áudio sem se tornar perceptível, o que permite reduzir o débito associado à representação codificada. O modelo psicoacústico é o principal factor que determina a qualidade do codificador.
Ele tem duas tarefas a realizar. Decidir que tipo de bloco usar e calcular a relação sinal/máscara (SMR) (valor do sinal na banda dividido pelo limiar de mascaramento).
Primeiro o áudio é convertido para o domínio da frequência, usando a Transformada Rápida de Fourier (FFT) para obter uma boa resolução de frequência para o cálculo correcto dos limiares de mascaramento. A saída da FFT é primeiro usada para analisar que tipo de sinal está a ser processado. Um sinal estacionário faz com que o modelo escolha um bloco longo, e um sinal mais transitório resulta num bloco curto. O tipo de bloco é usado depois no cálculo da MDCT. O modelo psicoacústico calcula o limiar de mascaramento mínimo para cada sub-banda, usando estes valores para calcular a SMR. O modelo então passa da SMR para a secção de controlo de distorção, quantificação e codificação para ser usada depois. A saída do modelo psicoacústico consiste nos valores para os limiares de mascaramento ou ruído permitido para cada sub-banda, o que é aproximadamente equivalente às bandas críticas da audição humana.
Existe ruído de quantificação num sinal digital, devido à existência de um número limitado de valores discretos para representar o sinal original. Se o ruído de quantificação for mantido abaixo do limiar de mascaramento para cada sub-banda, então o resultado da compressão não deverá ser distinguido do sinal original.
.: Quantificação e Codificação
Apesar de não ser normativo, normalmente usa-se um sistema com dois ciclos iterativos aninhados (ciclos de débito e distorção) na quantificação e codificação dos coeficientes MDCT. A quantificação é feita de modo que os valores maiores são codificados automaticamente com menos exactidão.
Os valores quantificados são codificados por codificação entrópica de Huffman. Para adaptar o processo de codificação a diferentes tipos de sinais musicais, selecciona-se uma tabela de Huffman óptima de um número de escolhas possíveis. Para ter uma melhor adaptação às estatísticas dos sinais, podem-se seleccionar diferentes tabelas de Huffman para diferentes partes do espectro de frequências.
Dado que a codificação Huffman é basicamente um método de comprimento de código variável e o ruído de quantificação deve ser mantido por baixo do limiar de mascaramento, um valor de ganho global (que determina o tamanho do passo de quantificação) e factores de escala (que determinam factores da forma do ruído para cada banda) são aplicados antes da quantificação real.
O processo de determinar o ganho e os factores de escala de cada banda óptimos para um bloco, débito e saída a partir do modelo psicoacústico, é feito pelos laços de iteração interior (débito) e exterior (distorção).
.: Ciclo de débito
O código de Huffman designa palavras de código mais curtas (mais frequentes) a valores quantificados menores. Se o número de bits resultante da codificação excede o número de bits disponível para codificar um bloco de dados, ele pode ser corrigido ajustando o ganho global (através de factores de escala) no qual resulta um passo de quantificação maior, conduzindo a valores quantificados menores. Esta operação é repetida até que o número de bits para a codificação Huffman seja suficientemente pequeno.
.: Ciclo de distorção
Para adaptar o ruído de quantificação ao limiar de mascaramento, são aplicados factores de escala a cada sub-banda. O sistema começa com um factor de escala de 1. Se o ruído de quantificação numa dada sub-banda for maior que o limiar de mascaramento (ruído permitido) de acordo com o modelo psicoacústico, o factor de escala para essa banda é ajustado para reduzir o ruído de quantificação. Dado que para conseguir um ruído de quantificação menor requer um maior número de passos de quantificação, consequentemente um débito mais elevado, o ciclo de débito deve ser repetido cada vez que são usados novos factores de escala. Por outras palavras, o ciclo de débito esta aninhado dentro do ciclo de distorção.
Este ciclo é executado até que o ruído fique abaixo do limiar de mascaramento para cada banda crítica.
.: Construção do Bitstream
O último passo no processo de codificação é produzir um bitstream de acordo com a norma.
O áudio codificado é armazenado em tramas, juntamente com alguns dados adicionais. Cada trama contém informação relativa a um bloco de áudio por canal. Uma trama consiste de um cabeçalho, dados de áudio e dados opcionais. O cabeçalho de cada trama descreve, entre outras coisas, qual a camada (layer), débito e frequência de amostragem. O uso de CRC é opcional.
Os dados codificados pelo codificador entrópico de Huffman e a sua informação colateral, são colocados na parte de dados de áudio, onde a informação colateral especifica o tipo de bloco, tabelas de Huffman e factores de ganho das sub-bandas.
.: Meta dados
Para além do áudio, é possível inserir informação variada nos ficheiros MP3. O formato mais usado para guardar essa informação, é o formato ID3. A versão mais actual é a ID3v2.
Cada etiqueta ID3v2 está dividida em tramas. Cada trama pode conter informação variada sobre a música contida no ficheiro, tal como título, álbum, artista, imagens, letra da música, etc. Este formato foi desenhado para ser flexível e extensível, pelo que é muito fácil adicionar novas funcionalidades ao ID3v2. É suportada a codificação de caracteres no formato Unicode .
De modo a ser eficiente, toda a informação é comprimida. Existe ainda um mecanismo que faz com que os leitores que não suportam ID3v2, simplesmente o ignorem.
A informação ID3v2 normalmente está no início do ficheiro, para possibilitar o seu uso em streaming , ao contrário do que acontece na versão ID3v1, em que a informação é armazenada no fim do ficheiro. É possível que o mesmo ficheiro contenha informação nos formatos ID3v1 e ID3v2. |


