| CARACTERÍSTICAS - CODIFICAÇÃO |
 |
| |
A captação múltiplas imagens implica num maior número de imagens a ser codificadas e transmitidas, surgindo então o problema da eficiência das ferramentas existentes, havendo necessidade de se desenvolver normas mais eficientes para a 3DTV.
Actualmente existem 3 métodos de codificação que estão a ser usados e melhorados. São eles 2D plus depth (2D+Z), Multiview Video Coding (MVC) e Multiview plus depth (MVD). |
| |
| 2D PLUS DEPTH |
2D-plus-depth (2D + Z) é um método de codificação de vídeo estereoscópico.
Este método codifica e transmite tramas 2D associadas a uma imagem designada por mapa de profundidade que corresponde à análise, pixel a pixel, da profundidade do objecto na imagem. Esta imagem tem 256 tons na escala de cinzento onde a cor branca corresponde ao plano mais aproximado e o preto ao plano mais afastado. Podemos ver em baixo na figura um exemplo destas duas imagens. Aquando da recepção do sinal, a exibição da imagem 3D é gerada com recurso à ferramenta Depth Image based Rendering (DIBR), fazendo uso do mapa de profundidade para atribuir o plano de exibição de cada objecto da imagem. |
| |
 |
| |
| As principais vantagens deste método são: |
- Compatível com televisores regulares 2D;
- Fácil de obter informação de conteúdo sintético (Z-buffers);
- Uma largura de banda apenas 10-20% maior em relação a conteúdos 2D, uma vez que o mapa de profundidade tem grande nível de factor de compressão.
|
| |
| As principais desvantagens são: |
- É necessário grande capacidade de processamento para gerar o mapa de profundidade;
- Não é possível ver áreas oclusas da imagem;
- As áreas oclusas introduzem maus artefactos visuais (bordas redondas nas altas frequências do mapa de profundidade);
- Não é adequado para sistemas de visualização com grandes ângulos de visão;
- Capacidade de alto processamento no descodificador.
|
| |
| MULTIVIEW VIDEO CODING |
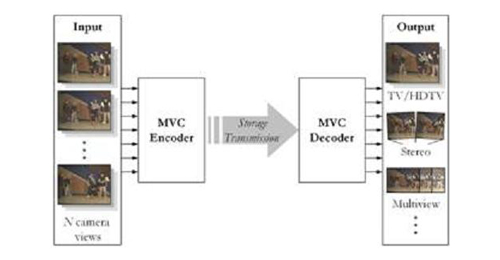
| Multiview Video Coding (MVC) é uma extensão da Advanced Video Coding (AVC) que oferece eficiência de codificação de vídeo multivista. A estrutura geral da MVC é ilustrado na figura abaixo. O codificador recebe N ligações de vídeo temporalmente sincronizadas e gera o bitstream. O descodificador recebe o bitstream, descodifica e gera os N sinais de vídeo. |
| |
 |
| |
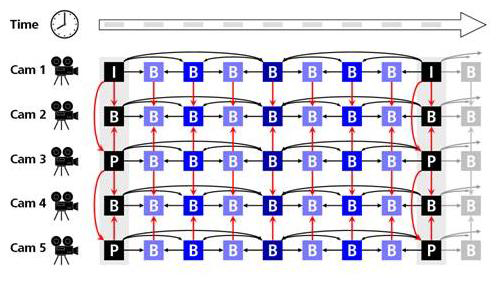
| Vídeo multivista contém uma grande dependência estatística entre cada vista, uma vez que todas as câmeras capturam a mesma cena de diferentes pontos de vista. Então, a fim de atingir uma boa eficiência de compressão, combina-se previsão temporal entre vistas. Como ilustrado na figura abaixo, é possível fazer previsão não só para as imagens de uma câmara, como para imagens de câmaras vizinhas |
| |
 |
| |
| As principais vantagens deste método são: |
- Áreas oclusas da imagem são registadas;
- Com várias vistas, grandes ângulos de visão podem ser cobertos.
- Maior noção 3D, sendo que a imagem difere com o ângulo de vista do espectador.
|
| |
| As principais desvantagens são: |
- Grande capacidade de processamento para interpolação do ponto de vista;
- Maior largura de banda disponível em relação ao 2D AVC, dependendo do número de vistas codificadas.
|
| |
| MULTIVIEW VIDEO PLUS DEPTH |
Este método é uma combinação entre 2D+Z e MVC.
Para este método, o número de vistas é reduzido em relação ao MVC porque vistas intermediárias podem ser facilmente interpoladas.
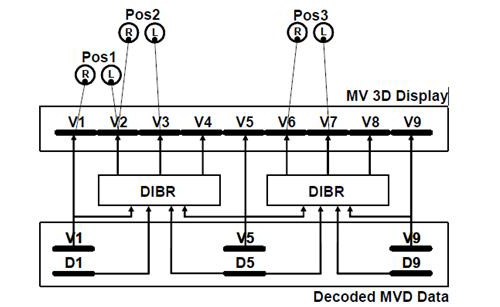
A cada vista está associado o seu mapa de profundidade que, com recurso à ferramenta DIBR, o descodificador tratará de exibir a imagem com efeito 3D.
A figura seguinte, ilustra o gerar de 3 imagens no descodificador: |
| |
 |
| |
| Principal vantagem deste método: |
- Requer menos largura de banda na transmissão que MVC, uma vez que precisa de menos imagens.
|
| |
| Principal desvantagem: |
- Requer grande nível de processamento no descodificador.
|
| |
